
안녕하세요!
이번 시간에는 간단한 머신러닝 태스크를 진행하고, 그 결과를 MLflow Tracking 서버에 저장하도록 하겠습니다.
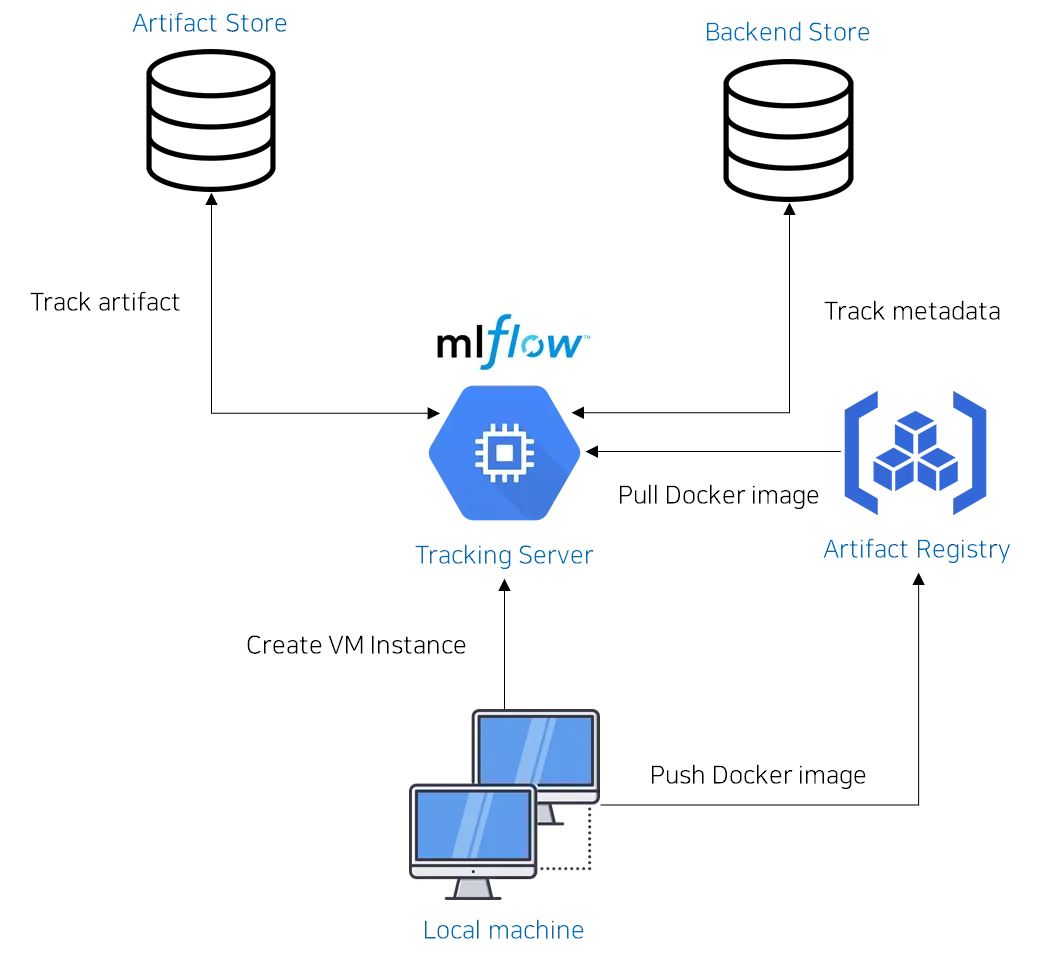
또한, MLFlow server와 연동된 GCP의 Artifact store 및 Backend store에 어떠한 데이터가 저장되어 있는지 확인해보죠!
MLFlow server와 GCP 연동에 관련된 내용은 앞선 포스팅(1~3편)을 참고해주시기 바랍니다.
또한, 머신러닝 태스크 수행 시 필요한 설정은 Hydra를 이용했습니다.
Hydra 사용 방법에 대한 자세한 내용은 Hydra를 이용한 설정 관리 프로젝트 포스팅(총 3편)을 참고해주세요!
프로젝트 링크
전체 코드는 아래 Github 링크에 있습니다!
ML Task
이번 시간에 다룰 머신러닝 태스크는 감성 분석(Sentiment Analysis)입니다.
총 5만 개의 데이터로 구성되어 있으며, Review와 Sentiment 컬럼이 포함되어 있어요!
결과적으로 Review를 통해 Sentiment(positive, negative)를 분류하는 task가 되겠습니다
코드
이번 시간의 핵심 코드는 model_registry.py 파일입니다.
해당 파일이 어떤 역할을 수행하는 지 함께 살펴보시죠!
# model_registry.py
import os
import numpy as np
import mlflow
import joblib
import hydra
from sklearn.base import BaseEstimator
from mlflow.models.signature import infer_signature
from mlflow.pyfunc import log_model
from hydra.utils import instantiate
from dotenv import load_dotenv
from src.trainer import evaluate
from src.model import SentimentClassifier
from config.config_schema import Config, setup_config
from utils.data import (
load_data,
split_data,
preprocess_data
)
# load environment variable in .env file
load_dotenv()
np.random.seed(2024)
def train_model_and_save_artifacts(configuration: Config):
# instantiate model for sentiment analysis
model: BaseEstimator = instantiate(configuration.model)
# load data
df = load_data(path='./data/imdb-dataset.csv')
# split data
train_df, test_df = split_data(df, test_size=0.3)
# preprocess data & serialize vectorizer
train_inputs, test_inputs, vectorizer = preprocess_data(train_df, test_df)
joblib.dump(vectorizer, "vectorizer.joblib")
# set tracking server
MLFLOW_SERVER_PORT = os.environ["MLFLOW_SERVER_PORT"]
mlflow.set_tracking_uri(f"http://localhost:{MLFLOW_SERVER_PORT}")
mlflow.set_experiment("sentiment-analysis")
# train & validate model + log artifacts
with mlflow.start_run():
# train and serialize model
model.fit(train_inputs, train_df["label"].values)
joblib.dump(model, "model.joblib")
# evaluate model and make confusion matrix figure
f1_score, figure = evaluate(
model=model,
test_inputs=test_inputs,
test_labels=test_df["label"].values,
class_names=test_df["sentiment"].unique().tolist()
)
figure.savefig("confusion_matrix.png")
print("F1 score: ", f1_score)
# log artifacts(including artifact)
mlflow.log_figure(figure, "confusion_matrix.png")
mlflow.log_metric(key='f1_score', value=f1_score)
mlflow.log_params(model.get_params())
# define model signature(model input & output shape)
signature = infer_signature(
model_input={
"review": test_inputs.toarray()
},
model_output=model.predict(test_inputs)
)
sentiment_classifier = SentimentClassifier()
artifacts = {
'vectorizer': "./vectorizer.joblib",
'model': "./model.joblib",
}
log_model(
artifact_path="model",
python_model=sentiment_classifier,
artifacts=artifacts,
signature=signature,
conda_env="./conda.yaml",
registered_model_name="basic-sentiment-classifier"
)
@hydra.main(config_name="config_schema", version_base="1.2")
def main(config: Config):
train_model_and_save_artifacts(configuration=config)
if __name__ == "__main__":
setup_config()
main()
Python
복사
핵심 내용
•
설정
◦
제일 먼저, setup_config() 메소드를 호출하여 감성 분석을 위해 필요한 모델 설정을 수행합니다. 모델 설정에는 어떠한 모델을 사용할 지, 그리고 모델 생성에 필요한 파라미터 정보가 있습니다.
◦
main() 메소드 실행 전, wrapper function으로서 hydra.main() 가 호출됩니다. 해당 함수를 통해 ‘config_schema’라는 이름을 가진 설정 노드를 가져옵니다. (Hydra Structured Config Schema)
◦
(Remind) 설정 노드는 key-value 형태로 구성되어 있으며, key는 노드의 이름, value는 dataclass 정의입니다.
•
main() 메소드
◦
먼저, ‘config_schema’ 라는 이름을 가진 설정 노드에서 dataclass 정보를 config 파라미터의 값으로주입 받습니다. 그 다음, 모델을 학습하고 아티팩트를 MLflow tracking server에 저장하는 역할을 수행합니다.
•
모델 객체화 및 데이터 처리
◦
Hydra의 instantiate() 메소드를 통해, dataclass가 목표(_target_ keyword)로 하는 모델을 객체화합니다.
▪
본 포스팅에서는 scikit-learn에서 제공하는 LogisticRegression 모델을 사용하였습니다.
◦
모델 학습 및 평가에 사용될 imdb dataset을 호출한 뒤, 전처리를 수행합니다.
▪
모델의 동작을 위하여, 텍스트 데이터를 실수형 벡터로 변환하는 과정이 필요합니다. 저는 Scikit-learn에서 제공하는 TfidfVectorizer를 사용했습니다.
▪
vectorizer는 모델 추론 과정에서도 필요한 부분입니다(전처리 수행). 따라서, joblib.dump() 메소드를 통해 vecorizer를 저장합니다.
•
MLflow tracking server 구성
◦
mlflow.set_tracking_uri(uri) 메소드 → MLFlow tracking server의 주소는 uri 파라미터의 인자와 같습니다.
▪
현재, MLflow server는 VM instance 내부의 컨테이너에서 구동되고 있습니다.
•
VM instance의 6100번 포트
▪
따라서, uri 파라미터 인자는 VM instance의 6100번 포트에 대응되는 주소 값입니다.
◦
mlflow.set_experiment(name) 메소드 → MLflow server 내에서 실험 정보를 기록하기 위한 Namespace를 결정하는 역할을 수행합니다.
•
모델 학습 및 평가
◦
fit() 메소드를 통해 객체화 된 모델을 학습하고, evaluate() 메소드를 통해 학습된 모델을 평가합니다.
◦
mlflow.log_params(), mlflow.metrics() 메소드를 통해 실험에 사용한 파라미터 정보와 평가 성능을 MLFlow tracking server에 저장합니다.
▪
이때, Backend store로서 GCP SQL을 지정했습니다. 따라서, GCP에 있는 데이터베이스에 관련 데이터가 자동으로 저장됩니다.
◦
학습된 모델 객체 또한 모델 추론 과정에서 반드시 필요한 부분입니다. 따라서, joblib.dump() 메소드를 통해 모델 객체를 저장합니다.
•
아티팩트 저장
◦
mlflow.pyfunc.log_model() 메소드를 통해 아티팩트를 MLflow tracking server에 저장합니다.
▪
mlflow.pyfunc 모듈은 Tensorflow, Pytorch, Scikit-learn 등 특정 머신러닝 프레임워크에 종속되지 않고, 통일된 모델 인터페이스를 제공하기 위하여 사용됩니다.
▪
◦
이때, 저장할 아티팩트는 학습된 모델과 vectorizer입니다. key-value 형식의 딕셔너리를 artifact 파라미터에 넘겨줍니다.
▪
key: 아티팩트 이름
▪
value: 아티팩트가 위치한 경로
▪
예: artifacts = {'vectorizer': "./vectorizer.joblib", 'model': "./model.joblib"}
◦
python_model 파라미터: 모델 추론을 위해 PythonModel 클래스 객체를 인자로 지정합니다. 이에 대한 자세한 내용은 model.py 스크립트에서 하겠습니다.
model.py
mlflow.pyfunc 모듈을 통해 특정 ML 프레임워크에 종속되지 않도록 모델의 인터페이스를 구현할 수 있다고 했습니다. 이때, 반드시 구현해야 할 메소드가 predict() 입니다.
쉽게 생각해보면, 모델의 궁극적인 목표는 추론을 수행하고, 그 결과를 사용자에게 알려주는 것이지요. 이를 위하여, 커스텀 모델의 predict() 메소드가 어떻게 동작할 지 정의하는 것은 당연한 처사입니다.
본 프로젝트에서는, model.py 파일을 통해 모델 인터페이스를 정의하였습니다. 자세한 내용은 아래 코드를 보면서 설명드리죠!
# src/model.py
from typing import Optional
import numpy as np
import pandas as pd
import joblib
from mlflow.pyfunc import PythonModel, PythonModelContext
# Reference: https://mlflow.org/docs/latest/python_api/mlflow.pyfunc.html
class SentimentClassifier(PythonModel):
def __init__(self):
self.vectorizer = None
self.model = None
# Optional
# When loading an MLflow model with load_model(), this method is called as soon as the PythonModel is constructed.
def load_context(self, context: PythonModelContext):
self.model = joblib.load(context.artifacts["model"])
self.vectorizer = joblib.load(context.artifacts["vectorizer"])
# mandatory
def predict(
self,
context: Optional[PythonModelContext],
input_df: pd.DataFrame
) -> np.ndarray:
return self.custom_predict(input_df)
def custom_predict(self, input_df: pd.DataFrame) -> np.ndarray:
inputs = self.vectorizer.transform(input_df["review"])
return self.model.predict(inputs)
Python
복사
커스텀 모델을 정의하기 위해서는, 반드시 mlflow.pyfunc.PythonModel 클래스를 상속해야합니다.
또한, 해당 클래스를 상속하는 과정에서 predict() 메소드를 반드시 구현해야 합니다. 중요한 부분이기에 계속 반복하여 설명드립니다
모델이 주어진 리뷰가 긍정적인지 부정적인지 분류하기 위해서는, 리뷰를 벡터로 변환하는 과정이 필요하다고 하였습니다. 따라서, 본 프로젝트에서는 predict() 메소드가 다음의 기능을 하도록 구현해야겠지요!
•
MLflow server에 저장된 vectorizer 객체를 불러옴
•
vectorizer 객체를 이용하여 리뷰를 벡터로 변환
•
모델은 벡터를 입력으로 받아, 리뷰의 성격을 예측(긍정/부정)
모델 학습 및 평가
그럼 본격적으로, 모델을 학습 시키고 성능을 평가해봅시다!
일단, Hydra 기능을 이용하여 바꿀 수 있는 파라미터가 무엇이 있는지 살펴보지요!
$ poetry run python model_registry.py --help
model_registry is powered by Hydra.
== Configuration groups ==
Compose your configuration from those groups (group=option)
model: logistic_regression
== Config ==
Override anything in the config (foo.bar=value)
model:
_target_: sklearn.linear_model.LogisticRegression
n_jobs: null
penalty: l2
C: 1.0
solver: lbfgs
fit_intercept: true
max_iter: 150
multi_class: auto
warm_start: false
l1_ratio: 0.7
Powered by Hydra (https://hydra.cc)
Use --hydra-help to view Hydra specific help
Bash
복사
저는 C, solver 값을 조정해보도록 하겠습니다.
$ poetry run python model_registry.py model=logistic_regression model.C=3 solver=newton-cg
F1 score: 0.897334318136037
Registered model 'basic-sentiment-classifier' already exists. Creating a new version of this model...
2024/02/20 11:15:46 INFO mlflow.store.model_registry.abstract_store: Waiting up to 300 seconds for model version to finish creation. Model name: basic-sentiment-classifier, version 12
Created version '12' of model 'basic-sentiment-classifier'.
Bash
복사
이번에는, UI를 통해 MLflow server를 조금 더 살펴보도록 합시다.
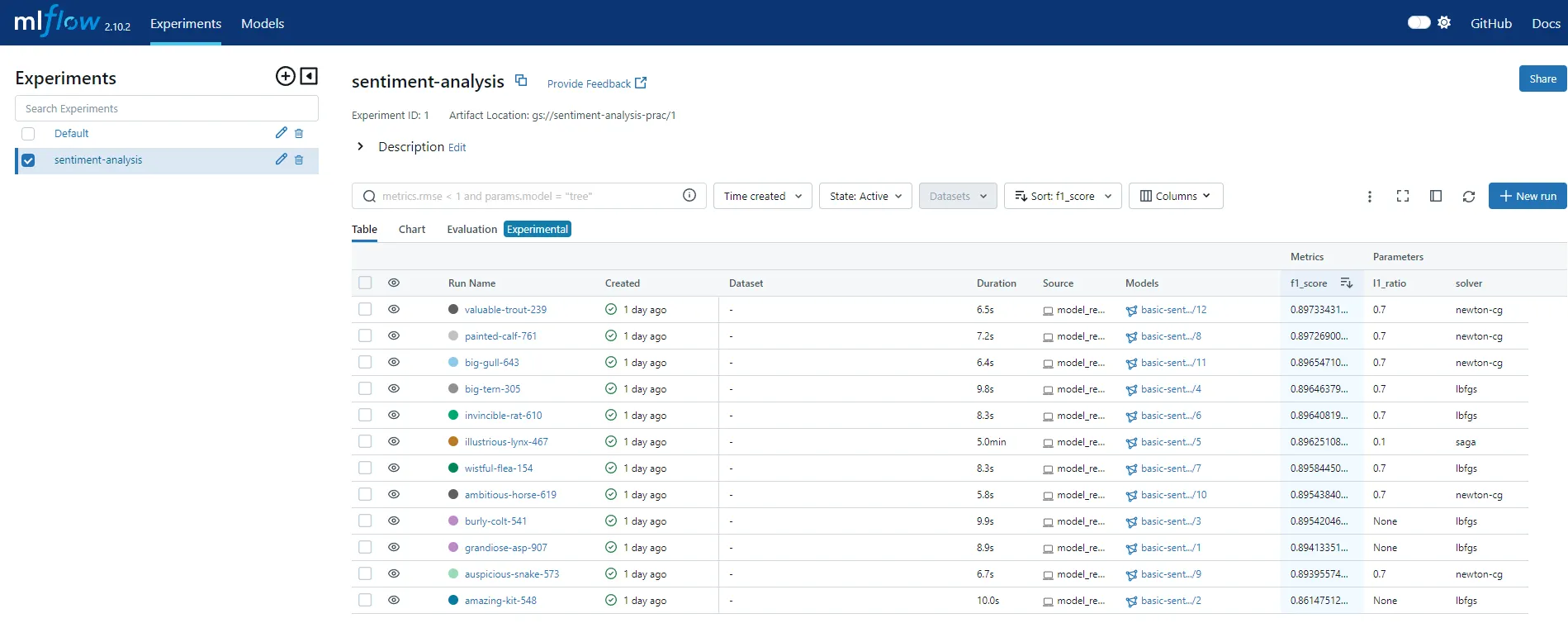
그림과 같이 run 단위로 각 실험에 대한 로그가 기록된 것을 볼 수 있습니다. 그 중에서 방금 진행한 실험의 로그를 같이 살펴보시죠
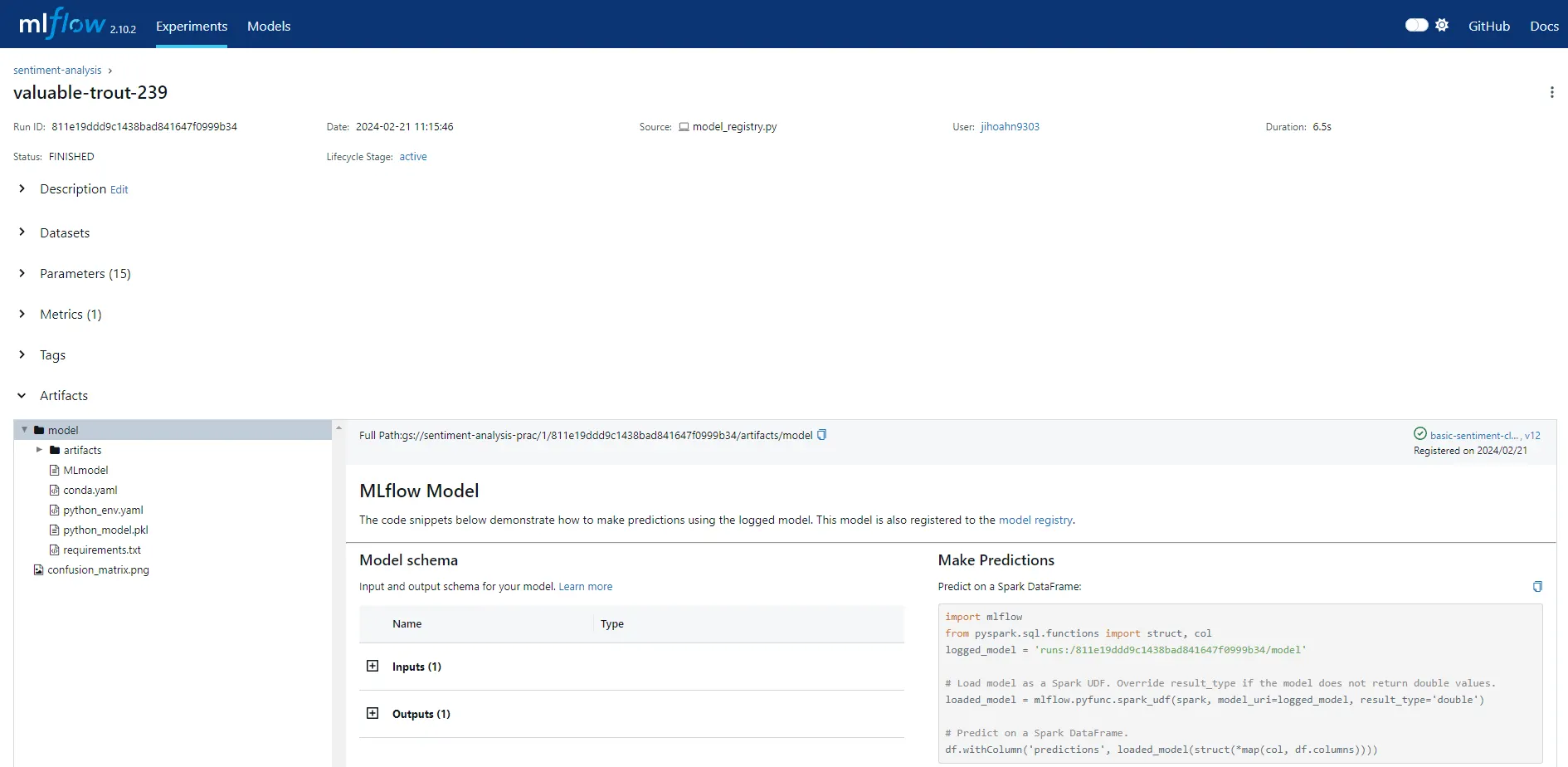
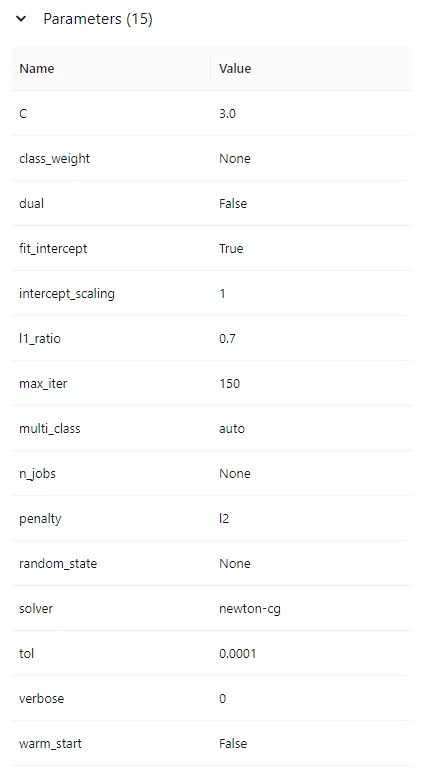
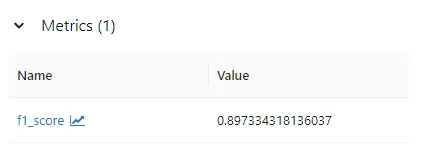
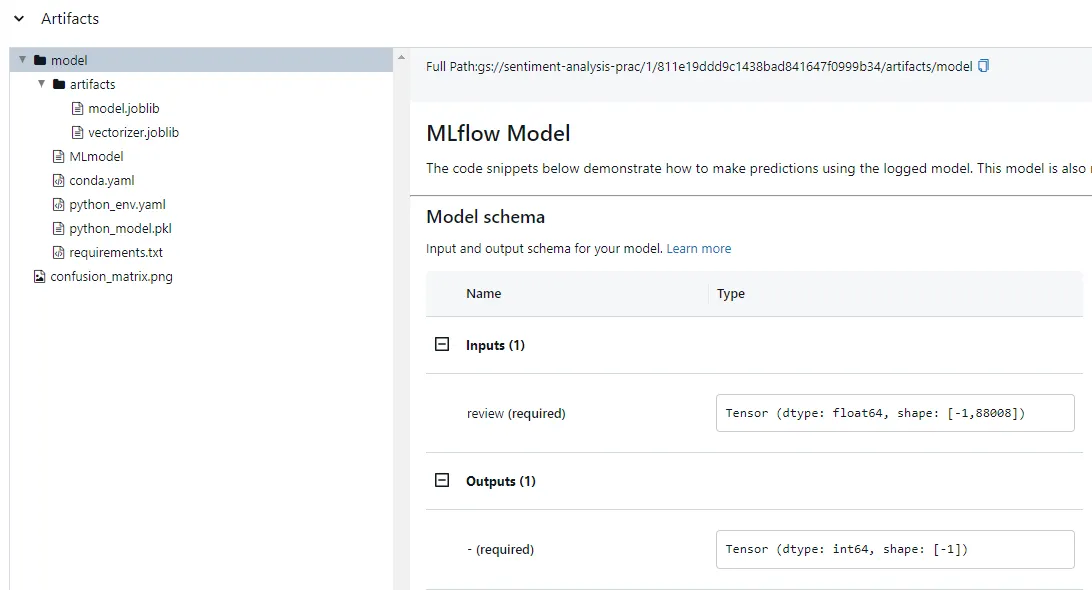
실험에 사용한 파라미터, 모델 성능, 아티팩트, 시그니처 등 여러 정보가 저장된 것을 확인할 수 있습니다.
load_model() 메소드를 호출하여 학습된 모델(커스텀 모델)을 불러올 때, 해당 모델은 자동으로 load_context() 메소드를 호출합니다. 이때, load_context() 메소드의 context 파라미터 값이 UI에서 확인할 수 있는 모든 내용을 의미해요! 예를 들어 아티팩트에 대한 내용은 context.artifacts 에 포함되어 있습니다.
•
학습된 모델 → context.artifacts[”model”]
•
vectorizer → context.artifacts[”vectorizer”]
Artifact
현재 MLFlow server의 Artifact store로서 Cloud Storage를, Backend store로서 Cloud SQL를 사용(연동)하고 있다고 말씀드렸습니다.
그렇다면, 실제로 클라우드 상에 아티팩트와 실험 관련 로그가 제대로 저장되어 있는 지 확인하도록 합시다.
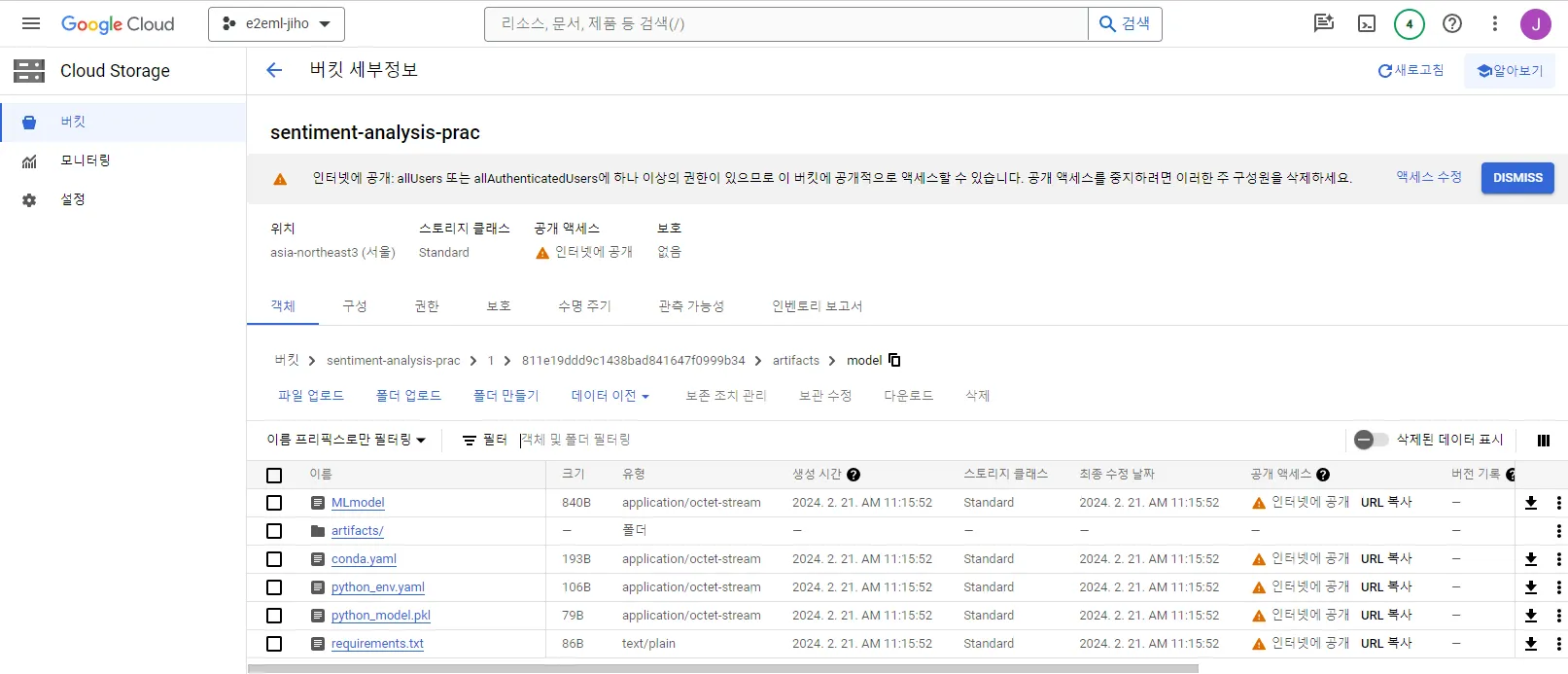
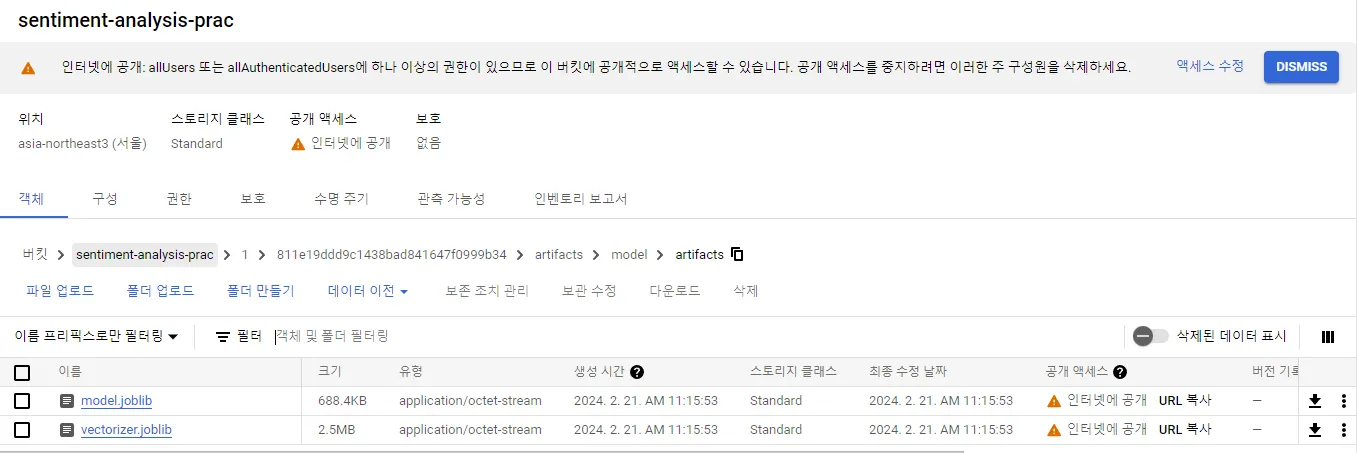
사진과 같이, Cloud storage 버킷에 학습한 Logistic Regression 모델, PythonModel 커스텀 모델 및 직렬화 된 vectorizer 객체가 저장된 것을 확인할 수 있습니다.
그렇다면, 이제는 Backend store도 확인해봐야겠지요?
저는 MySQL Workbench를 통해 Cloud SQL에서 구동중인 MySQL 데이터베이스에 접근하고자 합니다. 다음과 같이, Cloud SQL 데이터베이스의 IP, 포트, 유저, 비밀번호를 저장해둡니다.
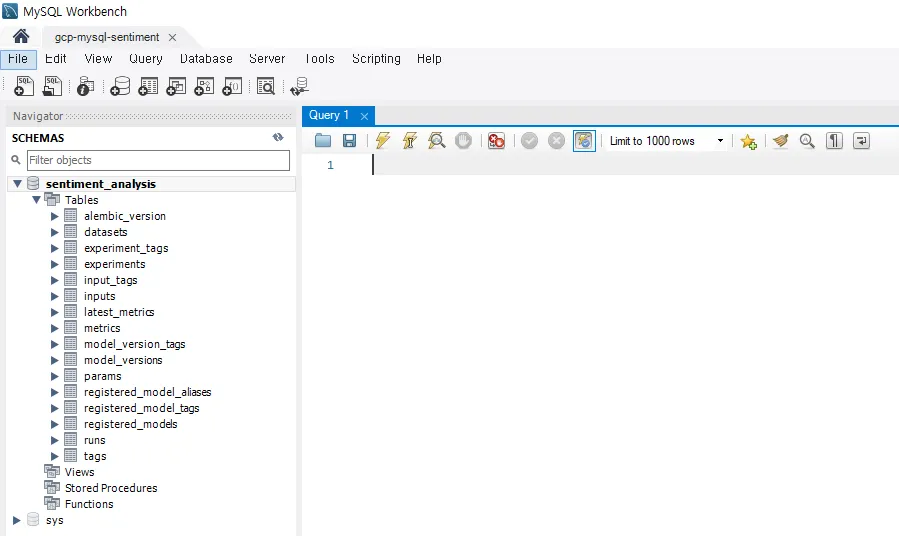
그 다음, 접속을 수행하면 다음과 같이 수많은 테이블이 존재하는 것을 확인할 수 있습니다! 바로 이 곳에 MLflow tracking server에서 기록한 실험 정보가 저장되어 있어요
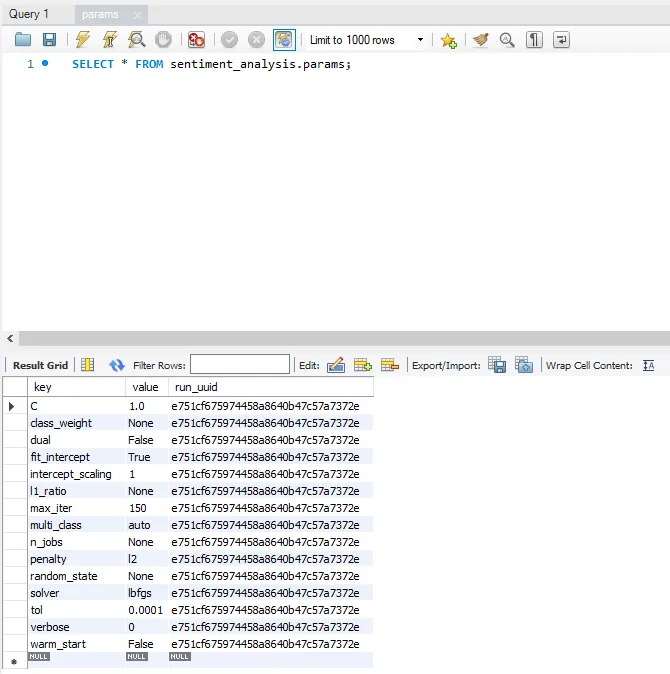
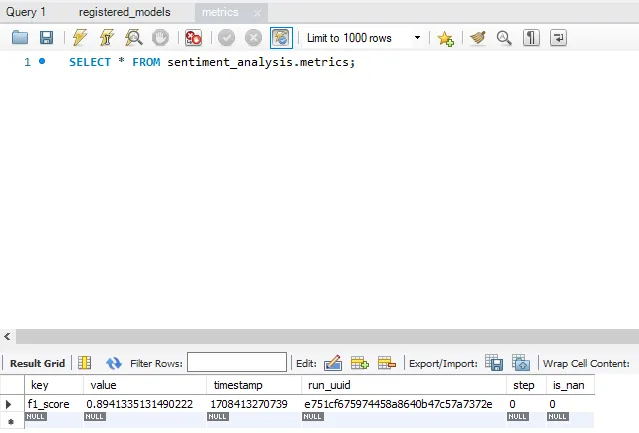
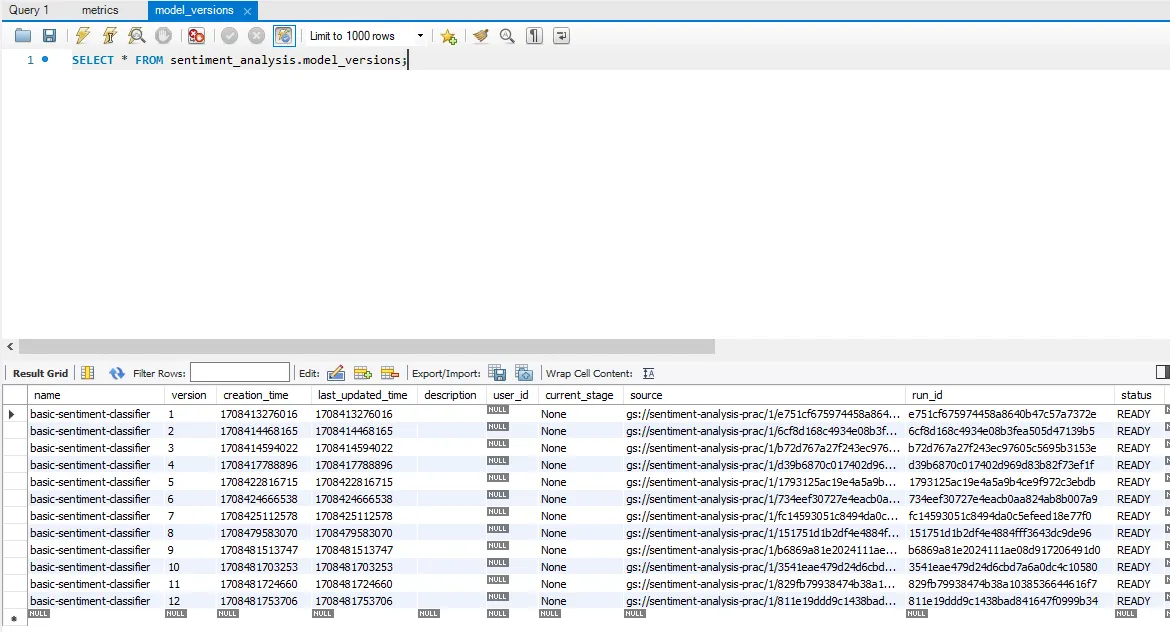
정리
이번 포스팅에서는 ML 실험을 실행하여 나온 결과물을 MLflow Tracking 서버에 기록하고, 관련 Artifact를 GCP에서 확인하는 시간을 가졌습니다.
다음에는 FastAPI 웹 프레임워크를 이용하여, GCP Cloud storage에 저장된 ML 모델을 서빙하는 주제로 찾아오겠습니다
그럼 안녕히 가세요
Reference
•