
데이터는 영원한 존재가 아니다
우연한 기회로, “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning”의 제목을 가진 논문을 읽게 되었습니다.
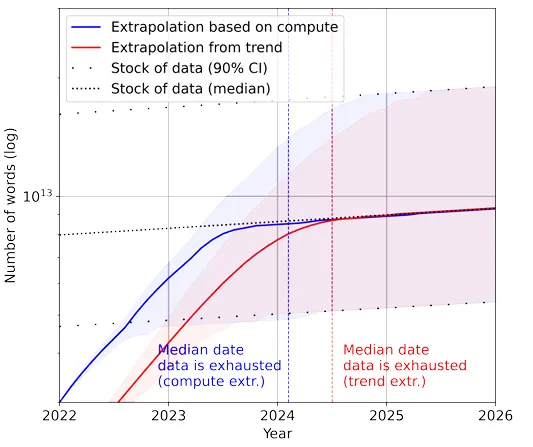
논문의 핵심 요지는 “현재 머신러닝 모델이 학습할 수 있는 데이터의 증가 속도가, 공개되어 있는 데이터의 증가 속도보다 빠르다” 입니다.
즉, ‘모델의 학습 데이터 소비 속도 > 공개 데이터의 생성 속도’로 정리할 수 있습니다. 결과적으로, 특정 시기에 접어들어서는 모델의 성능이 개선되지 않거나, 오히려 쇠락할 수 있는 포화 상태에 봉착할 수 있다는 것입니다. 특히, 고품질(High Quality) 언어 데이터는 현재 추세가 지속될 경우, 2026년 안에 고갈 상태(Ex)가 된다고 하니 심각한 상황이 아닐 수 없습니다.

고품질 데이터와 저품질 데이터
<고품질 데이터>
정의: 일반적으로, 고품질 데이터는 전문적인 기준에 따라 생성되고, 정제된 데이터를 의미해요! 이 데이터는 유용성이나 품질에 대한 검증을 거쳤기 때문에 훈련에 사용될 때 더 나은 모델 성능을 기대할 수 있습니다.
예시: 과학 논문, 서적, 뉴스 기사, 위키피디아 및 필터링된 웹 콘텐츠 등이 있습니다. 이러한 데이터 소스는 대개 데이터가 특정 품질 기준을 충족한다는 공통점이 있습니다.
<저품질 데이터>
정의: 저품질 데이터는 검증이나 필터링 과정 없이 인터넷과 같은 소스에서 직접 수집된 데이터를 의미해요. 이 데이터는 오류가 많거나, 불완전하거나, 관련성이 낮은 정보를 포함할 수 있습니다.
예시: 소셜 미디어 포스트, 사용자가 생성한 블로그 글, 포럼 댓글 등이 포함됩니다. 이러한 데이터는 종종 노이즈가 많고, 퀄리티가 일정하지 않을 수 있습니다.
저품질의 데이터가 고품질 데이터의 생성 속도보다 빠르다는 것을 감안했을 때, 저품질의 데이터를 적절하게 정제하여, 언어 모델에 투입하는 과정이 매우 중요하다고 볼 수 있습니다!
이러한 사실은, 우리가 일반적으로 모델을 학습하고 평가하기 위해서, 데이터를 나누는 과정을 생각하면 이해하기 편할 것 같습니다.
먼저, 학습(Train) 데이터와 평가(Test) 데이터를 일차적으로 분할하고, 학습 데이터 중 일부를 검증(Validation) 데이터로 분할하지요. 검증 데이터는, 모델이 학습 데이터를 사용하여 현상에 대한 일반화를 잘 수행하고 있는지 확인합니다. 또한, 평가 데이터는 모델이 이제껏 관찰하지 못한 새로운 데이터에 대한 일반화 정도를 평가하는 용도로 사용됩니다.
이때, 검증 데이터를 바탕으로 모델의 학습 정도를 평가하는 순간, 검증 데이터는 Out-of-date data가 됩니다. 또한, 평가 데이터를 모델에 적용하는 순간, 모델은 새로운 데이터를 관찰하였으므로, 이 또한 Out-of-date data가 됩니다. 데이터 수집의 비용을 고려하여, 동일한 데이터를 몇 번 정도는 반복하여 사용할 수 있습니다. 하지만, 언젠가는 (최대한 빠른 시일) 새로운 데이터를 수혈하여야 합니다.
저는, 이러한 상황을 근거로 하여 크게 두 가지의 결론을 내리게 되었습니다.
•
향후, LLM 연구 또는 LLM을 활용한 애플리케이션의 퀄리티는 Private data의 양과 퀄리티에 따라 결정이 될 것이다.
•
공개 데이터 이외에, 외부에서 추가적인 컨텍스트(또는 데이터)를 수혈하고, 이를 LLM이 효과적으로 사용할 수 있게 하는 것이 중요할 것이다.
RAG
RAG(Retrieval Augmented Generation, 검색 증강 생성)는 앞서 기술한 두 가지 결론을 커버할 수 있는 기술이라고 생각합니다. ‘검색 증강 생성’의 의미부터 살펴봅시다. 검색을 하여, 답변을 생성하는 데 그냥 생성하는 것이 아니라, 증강이라는 추가 과정을 거치게 됩니다. 무엇을 증강하고, 이를 LLM 모델에 어떻게 활용을 시킬까요?
RAG의 동작 원리
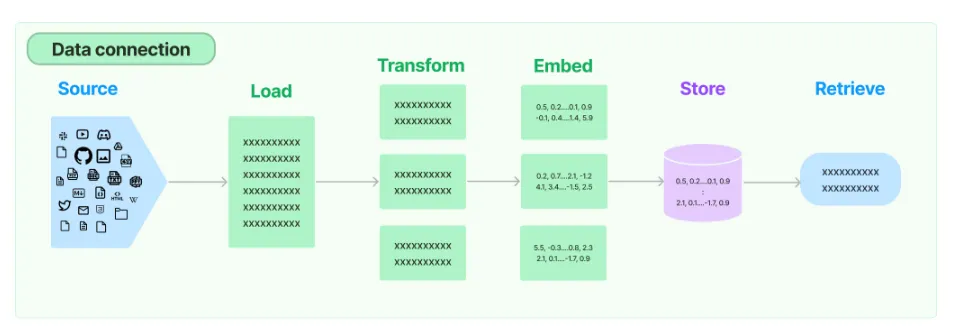
RAG의 동작 원리를 통해 앞선 의문점들을 해결해봅시다!
모델 외부에서 컨텍스트를 제공할 수 있는데, 이때 컨텍스트의 종류에는 제한이 없습니다. 즉, 비디오, 사진, 책, SNS 소셜 글 등 어떤 것이든 상관이 없다는 것이죠
이때, 컨텍스트를 추가적으로 제공하는 과정을 증강이라고 합니다. 다만, 컨텍스트를 모델이 이해할 수 있도록 몇 가지 과정이 필요합니다. 아래는 이와 관련된 컴포넌트를 순서대로 정리한 내용입니다.
•
DataLoader: 사용자에게 제공받은 컨텍스트 (또는 시스템이 추가적으로 수집한 데이터)를 메모리 상에 적재하는 역할을 수행합니다.
•
Splitter: 제공 받은 컨텍스트를 여러 Chunk로 분할하는 역할을 수행합니다. 이는 일부 컨텍스트만 참고하여, 사용자의 질문 의도에 적합한 데이터를 검색하기 위함입니다 일부 컨텍스트만 참고할 경우, 추후 Embedding 과정에서 필요한 토큰의 갯수를 줄일 수 있습니다(비용 절약).
일부 컨텍스트만 참고할 경우, 추후 Embedding 과정에서 필요한 토큰의 갯수를 줄일 수 있습니다(비용 절약).•
Embedding: 분할한 컨텍스트 Chunk를 벡터로 변환하는 역할을 수행합니다. 벡터를 이용하면, 사용자의 질문(Query)와 컨텍스트 간의 관계를 고려할 수 있게 됩니다.
◦
예시: 3차원의 벡터로 세상을 표현한다고 가정합시다! 이때, 벡터는 다음을 의미합니다. → [남성성, 여성성, 로열티]
◦
King → [0.9, 0.1, 1.0] 으로 가정합시다.
◦
Queen → [0.1, 0.9, 1.0] 으로 가정합시다.
◦
이때, Knight(기사)는 3차원의 공간 중 어떤 곳에 배치시키는 것이 괜찮을까요?
◦
물론, 주관의 차이가 있지만, 저는 기사의 남성성과 로열티를 고려하여 [1.0, 0.1, 0.6]으로 정하겠습니다!
◦
핵심은 모델은 벡터를 바탕으로 세계관을 이해할 수 있는 수단을 얻는다는 것입니다
•
Vector store(Retrieval): 임베딩 한 컨텍스트를 저장하는 공간, 일종의 데이터베이스입니다. Vector store를 통해, 사용자의 질문과 유사한 컨텍스트를 검색할 수 있습니다. 또한, 캐싱(Caching) 기능을 제공하여, 검색 시간을 최소화할 수 있습니다.
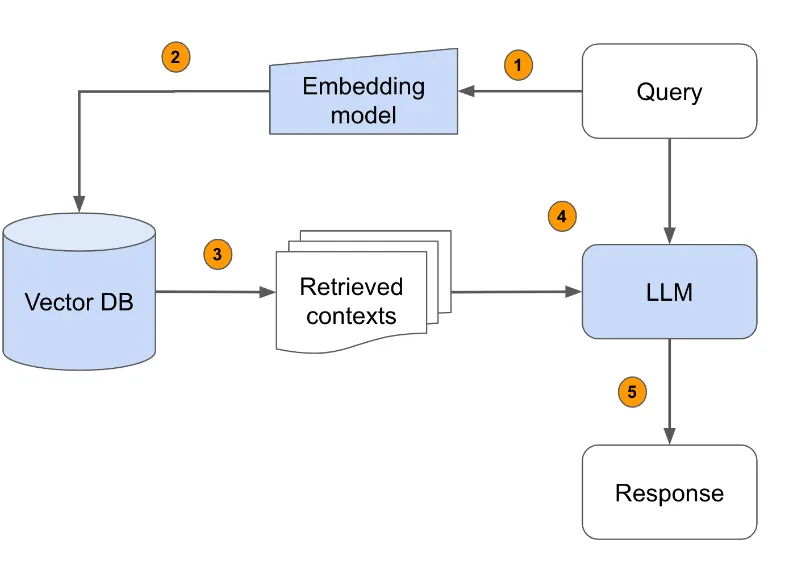
정리하면, RAG 동작 원리는 아래와 같습니다.
•
사용자가 LLM에 쿼리를 전송합니다 (Query → LLM).
•
쿼리는 Embedding을 통해, 벡터로 변환되며, Vector store(Vector DB)에도 전달됩니다 (1, 2번 과정).
•
Vector store에서는 벡터를 근거로, 쿼리와 유사한 컨텍스트를 추출합니다(3번).
•
새로 추출한 컨텍스트(증강된 컨텍스트)를 LLM에 전송합니다.
•
LLM은 기존에 학습한 데이터와 추가로 제공받은 컨텍스트를 토대로 답변을 생성합니다.
활용 예시
RAG에는 공개 데이터 뿐만 아니라, Private한 데이터도 함께 활용할 수 있어요! 이를 바탕으로, 개인화 컨텐츠 추천 서비스를 제공하는 과정을 생각해볼 수 있습니다.
예를 들어, 일주일 뒤에 회사 면접 일정이 있다고 하죠. ‘면접관이 나에게 어떠한 질문을 던질 것인가?’ 이 것이 가장 큰 화두가 될 것입니다. 우리는 열심히 포털 사이트에 직군에 관련된 면접 질문 리스트를 검색하고, 이에 대한 준비를 할 것입니다.
이 과정도 좋지만, 실제 면접 현장에서는 ‘나’, ‘내가 한 행동’을 주제로 질문이 나올 수 있습니다! 그리고, 그 질문은 내가 작성한 자기소개서 및 이력서를 참고하여 만들어질 수 있는 것이죠!
이때, 나의 자기소개서, 이력서 및 여러 포트폴리오 정보들을 Vector store에 저장하고 LLM이 필요할 때 활용할 수 있도록 해봅시다. 그러면, 직군과 관련된 공통 질문 뿐 아니라, ‘나’를 물어보는 질문 생성할 수 있겠지요! 결과적으로, Private한 정보를 추가로 제공하여 다양한 면접 질문을 생성할 수 있는 서비스를 만들 수 있을 것입니다
정리
이번 시간에는 RAG의 필요성과 자세한 동작 원리에 대해서 살펴봤습니다. 특히, 모델 학습 데이터의 고갈 속도를 보고 RAG 기술을 잘 활용하는 것이 중요하다는 것을 깨닫게 되었습니다. 앞으로는, RAG 기술을 활용한 애플리케이션을 직접 만들어보면서, 이 친구와 친숙해지려고 합니다
긴 글 읽어주셔서 감사합니다. 그럼 안녕