
Gallery
List
Search
데이터는 영원한 존재가 아니다
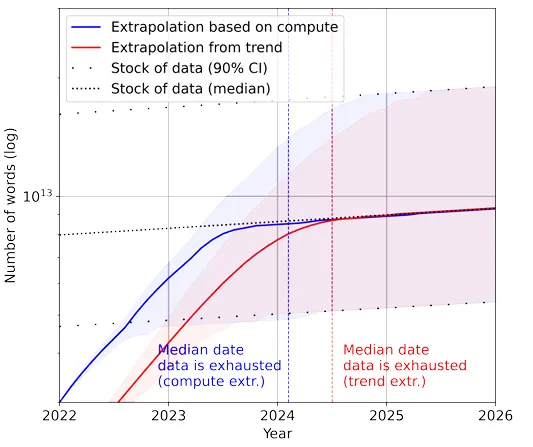
우연한 기회로, “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning”의 제목을 가진 논문을 읽게 되었습니다.
논문의 핵심 요지는 “현재 머신러닝 모델이 학습할 수 있는 데이터의 증가 속도가, 공개되어 있는 데이터의 증가 속도보다 빠르다” 입니다.
RAG의 중요성
요즘 LLM의 매력에 푹 빠져서, 오랜만에 노마드 코더님의 강의를 듣고 있는데요
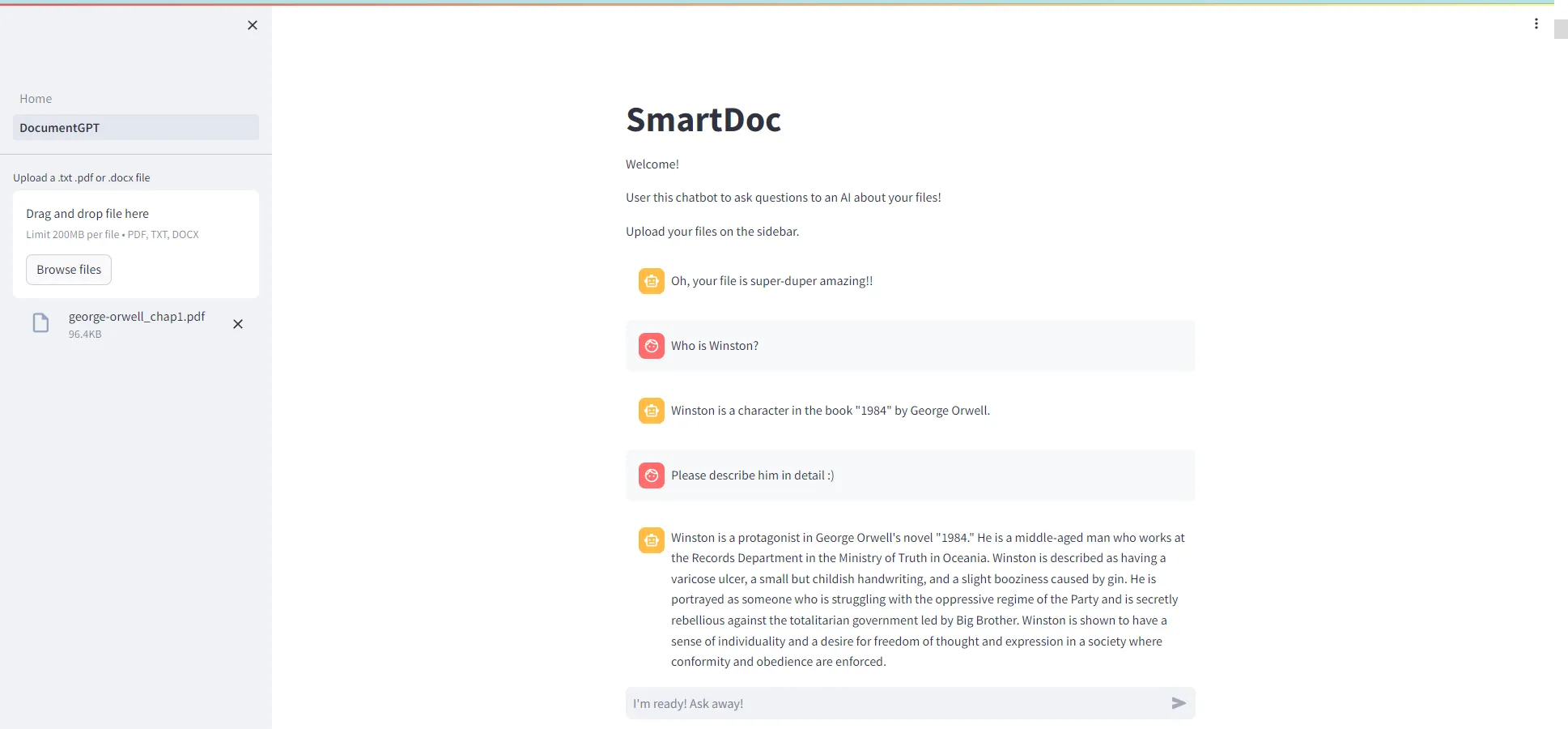
문서 정보를 제공해주는 챗봇 애플리케이션을 제작하는 과정이 재밌으면서, 정말 배울 점이 많아 이 곳에 정리하려고 합니다. 논문 내용을 정리하거나, 막히는 부분이 있을 때 ChatGPT를 활용하는데, 서비스를 클론 코딩을 해볼 수 있어 정말 좋았습니다!
목표는 챗봇 애플리케이션을 만드는 것이며, 챗봇은 주어진 문서에 대한 정보를 제공하는 역할을 수행합니다. 이때, 웹 애플리케이션 제작을 위해 Streamlit 프레임워크를 사용하였습니다. 또한, Langchain을 통해, LLM 기반 챗봇 구현을 수행했습니다.
전체 코드와 데모 영상은 아래 깃허브 링크에 있으니, 참고하시면 좋을 것 같습니다!
SmartDoc 챗봇 구축기

안녕하세요! 오랜만에 LLM 컨텐츠를 주제로 돌아왔습니다
LLM 관련 기술을 학습하고, 여러 프로젝트를 수행하면서 문득 한 가지 생각이 들더군요.
‘상품에 대한 설명을 참고하여 가격을 어느 정도 정확하게 예측을 할 수 있을까?’
Amazon 상품 가격 예측 봇 구축기(1) - 전처리

안녕하세요.
오늘은 Amazon 제품 가격 예측 봇 개발의 두 번째 시간입니다.
•
데이터 전처리
•
Baseline 모델 생성
•
LLM 파인튜닝 with GPT
Amazon 상품 가격 예측 봇 구축기(2) - Baseline 모델

두근두근
오늘은 드디어 OpenAI GPT-4o 모델을 파인튜닝하여 Amazon 상품 예측 봇을 만드는 날입니다.
•
데이터 전처리
•
Baseline 모델 생성
•
LLM 파인튜닝 with GPT
Amazon 상품 가격 예측 봇 구축기(3) - GPT-4o 파인튜닝

안녕하세요!
드디어 Amazon 상품 가격 예측 봇 구축기 마지막 세션입니다.
오늘은 오픈소스 모델을 대표하는 Llama-3.1을 파인튜닝하고, 성능을 평가하도록 하겠습니다.
•
데이터 전처리
•
Baseline 모델 생성
Amazon 상품 가격 예측 봇 구축기(4) - LlaMa-3.1 파인튜닝

안녕하세요!
저는 얼마 전, 우연하게 모두의 AI 케인님의 유튜브 영상을 시청하였습니다.
AI Agent에 대한 개념과 필요성에 대해 설명을 기막히게 잘 해주시더라구요!
덕분에 해당 주제에 대해 큰 흥미와 관심을 가지게 되었고, 본격적으로 Deep-dive하게 된 동기가 되었습니다 :)
vLLM 기반 AI Agent 구축기
Workflow
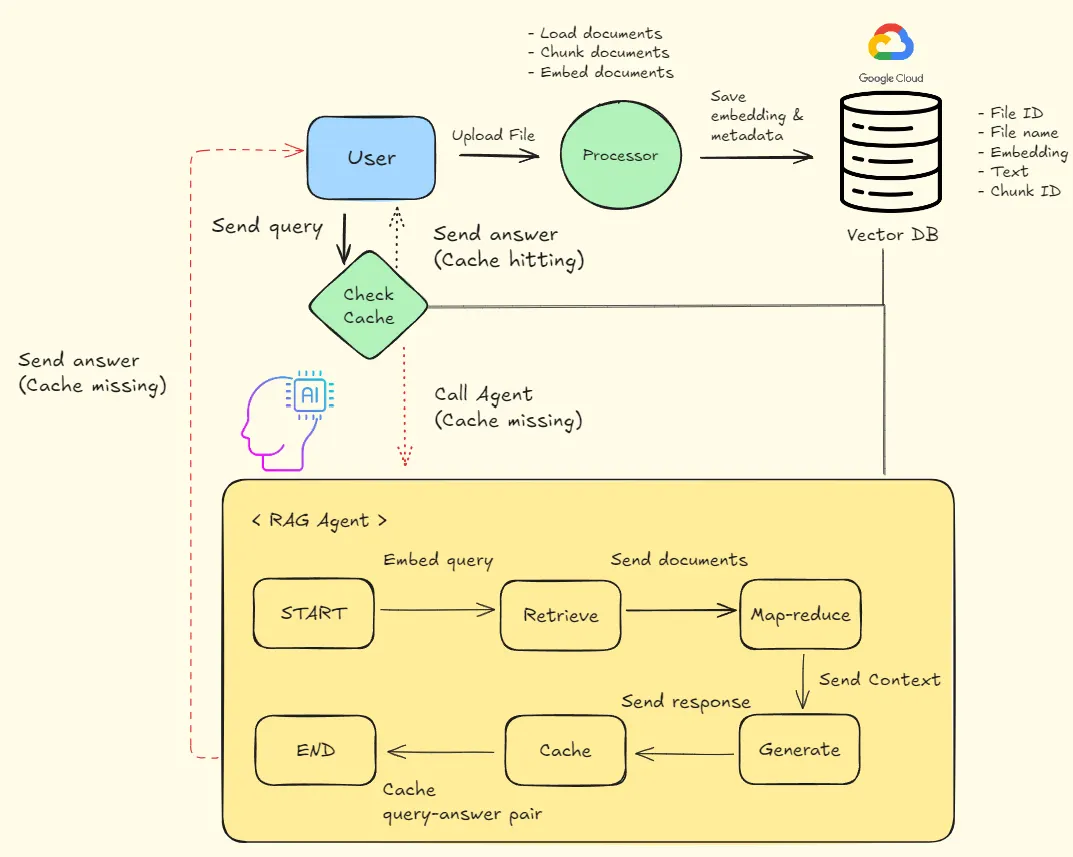
전체 프로세스는 다음과 같습니다.
•
캐시 시스템
•
파일 전처리(Loader, Chunking, Embedding, Vector database)
•
RAG Agent
RAG Agent 구축기
Text-to-SQL 파인튜닝에 관련된 핵심 주제 및 관련 레퍼런스를 정리하는 공간입니다.
Topic 1. 병렬 처리를 통한 SQL 질문 생성
•
Use case: SQL 생성 목적에 따라, 별도의 분기를 생성하여 그래프를 실행한다 > 전체 그래프 실행 시간을 단축시킬 수 있다.
•
핵심 키워드
◦
병렬 실행(Parallel execution)
▪
팬아웃(Fan-out): 하나의 노드로부터 여러 개의 노드를 생성하는 과정
▪
팬인(Fan-in): 여러 노드의 실행 결과를 취합한 후, 하나의 노드에 전달하는 과정
•
고려 사항: 노드가 접근하는 각 상태 값은 reducer 함수를 통해 관리된다. 따라서, 취합된 SQL 질문을 저장하는 변수에 대해 별도의 reducer 함수를 구현해야할 수도 있다 (예: 중복 데이터 제거).
•
레퍼런스
◦
An agent for interacting with a SQL database (SQL 쿼리 생성 및 평가 에이전트 튜토리얼)
Topic 2. 멀티턴
•
Use case: SQL 구문 생성 및 검증이 한 cycle에 끝나지 않고, 여러 cycle을 수행해야 할 수 있다. 예를 들어, SQL 검증 시 특정 기준을 만족하지 못하는 경우, 다시 SQL 구문을 생성하여 평가를 수행해야 한다. > Loop 구현 시 멀티턴 방식을 생각해볼 수 있다.
•
레퍼런스
◦
▪
해당 튜토리얼에서는, Interrupt / Command 기반 Human-in-the-loop를 통해, 여행지와 숙박 시설을 추천하는 agent 구현을 다룸

Topic 3. 메모리 스토어
•
Use case: SQL 쿼리 생성을 위해 필요한 정보를 저장
◦
SQL 쿼리 생성을 위해 병렬적으로 노드를 실행할 때(superstep), 필요한 정보가 있음
▪
테이블 이름 / 설명
▪
각 테이블에 속한 컬럼 정보(이름, 용도, 자료형 등)
◦
위에 언급한 정보는 공통적으로 필요한 정보이므로, 한 개의 Store에 정보를 저장함.
▪
Graph state에 스키마 정보를 저장하지 않아도 되므로, in-memory 리소스를 최소화할 수 있음(병렬 처리를 수행하는 노드마다 스키마 값을 소유하는 상황을 방지할 수 있음).
▪
스키마 정보를 JSON 형식으로 전처리하고, Store(예: PostgreStore)에 저장하는 과정을 수행해야 함.

Text-to-SQL 파인튜닝을 위한 LangGraph 레퍼런스 정리