LLM
Gallery
List
Search
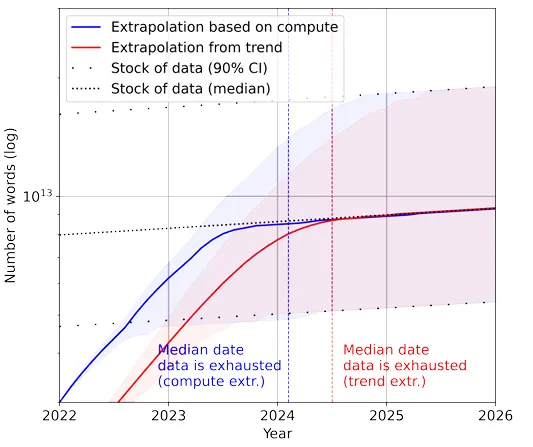
데이터는 영원한 존재가 아니다
우연한 기회로, “Will we run out of data? An analysis of the limits of scaling datasets in Machine Learning”의 제목을 가진 논문을 읽게 되었습니다.
논문의 핵심 요지는 “현재 머신러닝 모델이 학습할 수 있는 데이터의 증가 속도가, 공개되어 있는 데이터의 증가 속도보다 빠르다” 입니다.
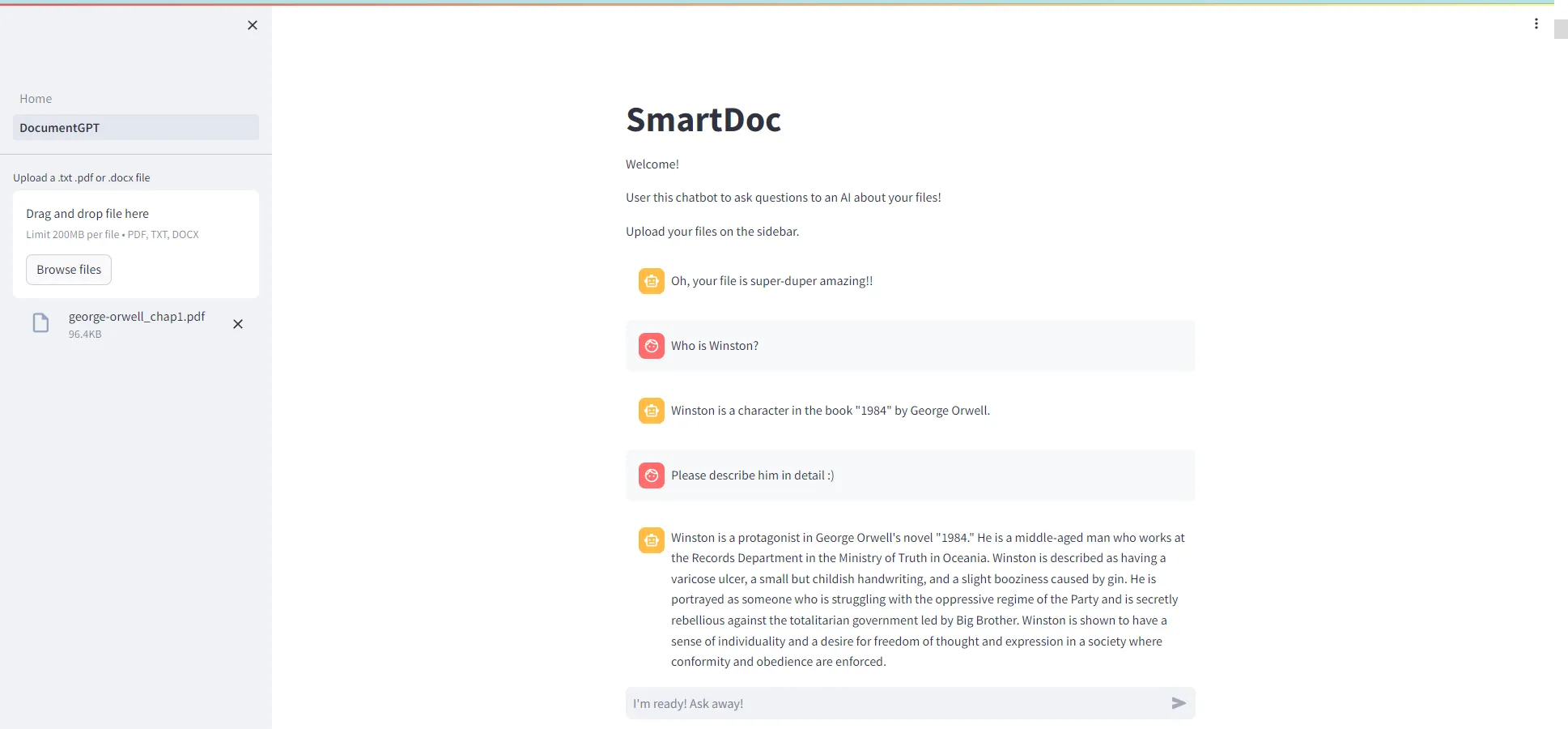
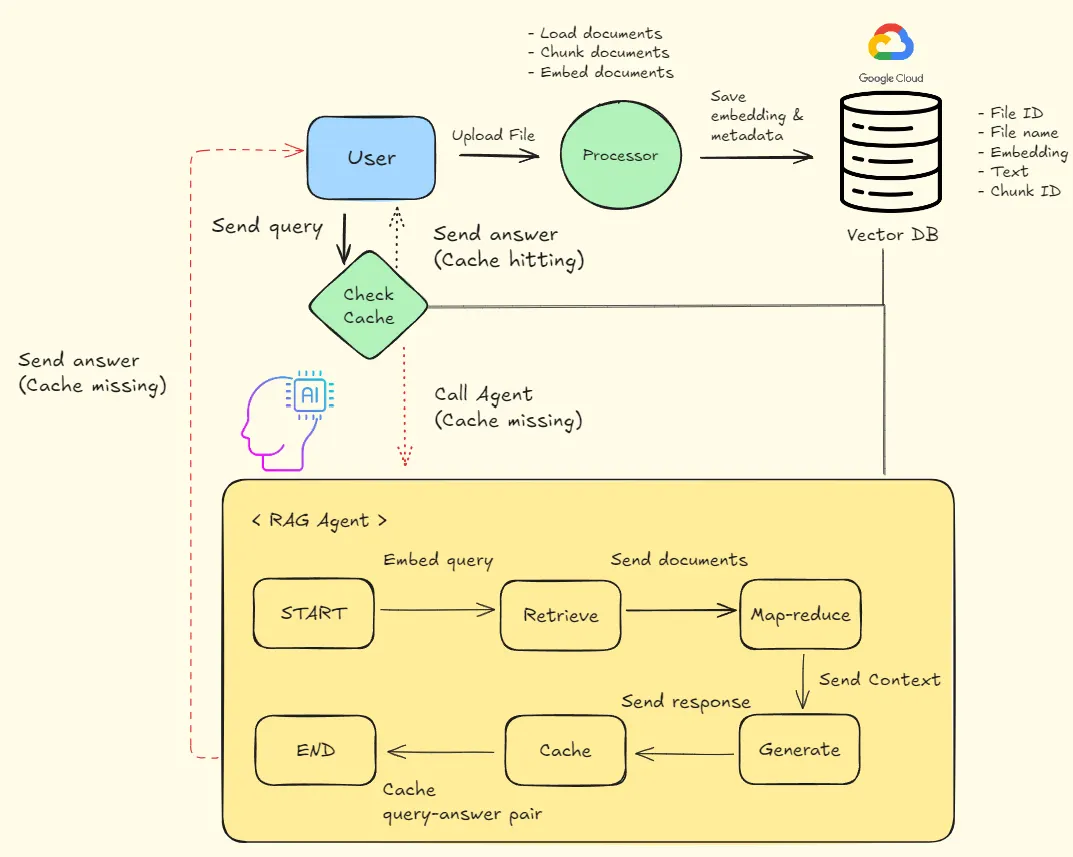
RAG의 중요성