

안녕하세요!
저는 얼마 전, 우연하게 모두의 AI 케인님의 유튜브 영상을 시청하였습니다.
AI Agent에 대한 개념과 필요성에 대해 설명을 기막히게 잘 해주시더라구요!
덕분에 해당 주제에 대해 큰 흥미와 관심을 가지게 되었고, 본격적으로 Deep-dive하게 된 동기가 되었습니다 :)
•
주제: RAG(Retrieval-Augmented Generation)와 AI Agent 기능을 활용한 문서 검색 봇 구축
•
개선사항: 다수의 유저를 상대로 한 LLM 모델 서빙 방법 개선
◦
비동기 API 처리를 활용 → 리소스 사용량 절감, 단일 시간 당 처리량 증가
◦
프레임워크 도입을 통한 추론 속도 개선 및 처리량 개선
▪
Groq, vLLM 등의 프레임워크 도입 고려
◦
LLM 모델 사용처 점검
▪
특정 phase에서 LLM 모델을 꼭 사용할 필요가 있는지 점검할 것
▪
LLM 모델을 빈번하게 사용할 수록, AI Agent로부터 결과를 받기까지 상당한 시간이 걸리기 때문
◦
대규모 서비스를 대비한 아키텍처 고려 → 메시지 브로커 시스템
▪
비동기 처리
▪
부하 분산 → 다수의 LLM 인스턴스에 작업을 적절하게 분배
▪
버퍼링 → 브로커가 수많은 request를 버퍼링함으로써, message가 유실되는 상황을 최소화
정말 많은 개선 사항들이 언급되었는데요!
이번 시간에는 vLLM 프레임워크 도입을 통해, 문서 검색을 하는 AI Agent를 구성하려고 합니다.
바로 출발하시죠~
AI Agent 구조 설명
본 프로젝트에서 사용하는 AI Agent의 구조를 시각화 한 그림은 아래와 같습니다.
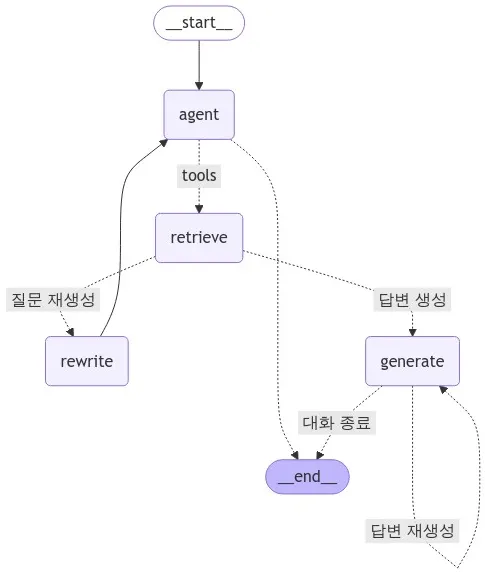
•
사용자의 질문(쿼리)를 받아 agent 노드에 전달합니다. agent 노드는 사용자의 질문에 바로 대답할 수 있는지 판단합니다.
◦
만약, 추가 작업이 필요 없다면, 대답 후 대화를 종료합니다.
◦
질문에 바로 대답할 수 없는 경우, 문서 탐색을 위해 retrieve 노드로 사용자의 질문을 전달합니다.
•
retrieve 노드는 벡터 데이터베이스에서, 사용자의 쿼리와 가장 관련성이 높을 것으로 판단되는 문서(Document)를 추출합니다.
◦
라우팅 함수를 사용하여, rewrite 노드(질문 재생성) 혹은 generate 노드(답변 생성) 중 어떤 노드로 결과 값(추출 문서)을 전달할지 결정합니다.
•
rewrite 노드에서는, 기존 사용자의 질문을 재생성함으로써, 가장 관련성이 높은 문서를 추출할 수 있도록합니다.
◦
LLM 모델을 사용하여, 사용자의 질문 의도에 벗어나지 않도록 재생성을 합니다.
•
generate 노드에서는, 제공 받은 문서(context)를 참고하여 사용자의 의도에 맞는 답변을 생성합니다.
◦
라우팅 함수를 사용하여, 생성된 답변을 검증합니다. 이때, 기준에 부합하지 않는 답변이 나올 경우, 다시 답변을 생성하도록 합니다.
실행 환경
본 코드는 Google Colaboratory 플랫폼에서 실행하였으며, 모델 구동을 위해 A100 GPU를 사용했습니다.
따라서, Colab 관련 코드가 일부 포함되어 있음을 미리 알려드립니다 :)
전체 코드는 아래에 첨부하였습니다.
라이브러리 설치
먼저, 본 프로젝트에서 필요한 라이브러리를 설치해줍니다.
!pip install langchain langgraph openai langchain_openai langchain_community langchain_huggingface langchain_chroma tiktoken vllm pypdf
Python
복사
드라이브 마운트
검색에 사용할 문서와 LLM 모델을 Working 디렉토리에 마운트합니다.
본 프로젝트에서 사용한 문서와 LLM 모델 정보는 다음과 같습니다.
•
•
from google.colab import drive
drive.mount('/content/drive')
Python
복사
vLLM을 통한 모델 서빙 서버 구축
Colab에서, 백그라운드로 vllm 서버가 구축될 수 있도록 다음과 같이 nohup 커맨드를 사용했습니다.
!nohup python -m vllm.entrypoints.openai.api_server \
--model /content/drive/MyDrive/LLM/ai_agent/Qwen2.5-3B-Instruct-GPTQ-Int4 \
--host 0.0.0.0 --port 8888 --max-model-len 4096 --trust-remote-code --gpu_memory_utilization 0.25 \
--kv-cache-dtype fp8 --dtype bfloat16 \
--enable-auto-tool-choice --tool-call-parser hermes > output.log 2>&1 &
Bash
복사
•
python -m vllm.entrypoints.openai.api_server : OpenAI 기반 API를 통해 vllm 서버와 통신할 수 있도록 합니다.
•
--model : 사용할 모델이 저장된 로컬 경로를 입력합니다.
•
--gpu_memory_utilization : KV(Key-Value) 캐시 구축에 할당할 GPU 메모리 양을 기재합니다. 본 프로젝트에서는 전체 GPU RAM의 25%(약 10GB)을 할당합니다. 기본 값은 0.9입니다.
•
--enable-auto-tool-choice : LLM 모델이 Tool calling을 사용할 수 있도록 합니다. 본 프로젝트의 경우, LLM 모델이 자체적으로 판단하여, 사용자의 질문에 답변할 수 없는 경우, retriver 노드를 자동으로 호출합니다.
ngrok 플랫폼을 통한 터널링 수행
외부에서 Colab 내에서 동작하는 vllm 서버에 접근하기 위해서는 터널링 과정이 필요합니다.
다시 말해, 외부에서 로컬 호스트에 띄어져 있는 vllm 서버와 통신할 수 있도록 합니다. 이를 위해 저는 ngrok 플랫폼을 활용했습니다. ngrok 플랫폼에 회원가입할 때 제공되는 token이 있습니다. 이를 활용하도록 합니다.
!pip install pyngrok
from pyngrok import ngrok
ngrok.set_auth_token("YOUR TOKEN") # 회원 가입 후 제공되는 token 값을 입력해주세요.
inference_tunnel = ngrok.connect("8888")
inference_tunnel
>> <NgrokTunnel: "https://4f97-34-55-193-101.ngrok-free.app" -> "http://localhost:8888">
Python
복사
•
ngrok.connect() 함수를 호출할 때, 8888번 포트를 입력했습니다. 이는 앞서 vllm 서버를 구동하는 과정에서, 접근 가능한 포트를 8888로 지정했기 때문입니다.
•
클라이언트는 터널링 후 얻은 도메인 주소를 통해 vllm 서버와 통신할 수 있습니다.
◦
여기서는 https://4f97-34-55-193-101.ngrok-free.app
테스트 수행
vllm 서버에 접근할 수 있는지 확인하기 위해 테스트를 수행하였습니다. 아래와 같이 vllm 서버에서 현재 사용할 수 있는 모델 정보가 잘 출력된 것을 확인할 수 있네요!
!curl https://4f97-34-55-193-101.ngrok-free.app/v1/models
>>
{
"object":"list",
"data":[
{
"id":"/content/drive/MyDrive/LLM/ai_agent/Qwen2.5-3B-Instruct-GPTQ-Int4",
"object":"model",
"created":1730592875,
"owned_by":"vllm",
"root":"/content/drive/MyDrive/LLM/ai_agent/Qwen2.5-3B-Instruct-GPTQ-Int4",
"parent":null,
"max_model_len":4096,
"permission":[
{
"id":"modelperm-e17b8393fda24858add0d7a7c9ebc92c",
"object":"model_permission",
"created":1730592875,
"allow_create_engine":false,
"allow_sampling":true,
"allow_logprobs":true,
"allow_search_indices":false,
"allow_view":true,
"allow_fine_tuning":false,
"organization":"*",
"group":null,
"is_blocking":false
}
]
}
]
}
Bash
복사
변수 설정
OpenAI API를 이용하여, vllm 서버와 통신하기 위해 필요한 변수를 정의합니다.
OPENAI_KEY = 'EMPTY' # 실제 OpenAI 서버와 통신하는 것이 아니므로, 'EMPTY'로 지정했습니다.
OPENAI_API_BASE = 'https://4f97-34-55-193-101.ngrok-free.app/v1' # ngrok 터널링 후 얻은 도메인 주소입니다.
MODEL_PATH = '/content/drive/MyDrive/LLM/ai_agent/Qwen2.5-3B-Instruct-GPTQ-Int4' # 사용할 모델 파일이 존재하는 로컬 경로입니다.
Python
복사
라이브러리 불러오기
AI Agent 구축에 필요한 라이브러리를 import합니다.
import re
from typing import Annotated, Sequence, TypedDict, Literal
from langchain_community.document_loaders import PyPDFLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import ChatOpenAI
from pydantic import BaseModel
from langchain_huggingface import HuggingFaceEmbeddings
from langchain.evaluation import load_evaluator
from langchain.tools.retriever import create_retriever_tool
from langchain_core.messages import BaseMessage, HumanMessage
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langgraph.prebuilt import ToolNode, tools_condition
from langgraph.graph import END, StateGraph, START
from langgraph.graph.message import add_messages
Python
복사
RAG에 필요한 요소 정의
RAG에 필요한 요소를 정의합니다.
# Data loader
loader = PyPDFLoader("/content/drive/MyDrive/LLM/ai_agent/혁신성장_정책금융_동향.pdf")
docs = loader.load_and_split()
# Initialize a text splitter with specified chunk size and overlap
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=250, chunk_overlap=50
)
# Split the documents into chunks
doc_splits = text_splitter.split_documents(docs)
# Embedding for retriever
# 임베딩 모델로서, Huggingface에 업로드 된 BAAI/bge-m3 를 사용했습니다.
model_name = "BAAI/bge-m3"
hf_embeddings = HuggingFaceEmbeddings(
model_name=model_name,
)
# Retriever
vectorstore = Chroma.from_documents(
documents=doc_splits,
embedding=hf_embeddings,
)
retriever = vectorstore.as_retriever(k=4)
# Instantiate LLM
llm = ChatOpenAI(
model=MODEL_PATH,
api_key=OPENAI_KEY,
openai_api_base=OPENAI_API_BASE,
max_tokens=1024,
temperature=0
)
Python
복사
•
랭체인에서 제공하는 ChatOpenAI 클래스를 사용합니다. 이를 통해 OpenAI에 있는 모델을 사용할 수 있습니다.
◦
하지만, 본 프로젝트에서는 로컬에 저장한 오픈 소스 모델을 사용합니다. → model 값으로 로컬 경로를 지정했습니다.
◦
특히, openai_api_base 인자 값으로 vllm 서버 주소를 제공한 것이 핵심입니다!!!
◦
결과적으로, OpenAI API를 통해(invoke() 등) vllm 서버에 존재하는 모델을 호출할 수 있습니다.
# create tool for retriever
retriever_tool = create_retriever_tool(
retriever=retriever,
name="retrieve_pdf_file",
description="혁신성장 정책 금융과 관련한 질문을 처리하기 위한 도구입니다.",
)
tools = [retriever_tool]
Python
복사
•
LLM 모델이 사용할 Tool을 정의하였습니다 → retriever tool
•
벡터 데이터베이스(Chroma)에서 사용자의 쿼리와 가장 관련성이 높을 것으로 판단되는 문서(Document)를 반환합니다.
LangGraph를 이용한 Graph 정의
노드의 상태 값
각 노드는, message의 시퀀스를 저장합니다. 즉, 대화 내용 기록을 저장합니다. LangGraph의 add_messages() 함수를 통해, 메시지가 누적될 있도록 합니다.
class AgentState(TypedDict):
# The add_messages function defines how an update should be processed
# Default is to replace. add_messages says "append"
messages: Annotated[Sequence[BaseMessage], add_messages]
Python
복사
Agent 노드 설정
def agent(state: AgentState):
"""
Invokes the agent model to generate a response based on the current state. Given
the question, it will decide to retrieve using the retriever tool, or simply end.
Args:
state (messages): The current state
Returns:
dict: The updated state with the agent response appended to messages
"""
print("---CALL AGENT---")
messages = state["messages"]
llm_with_tools = llm.bind_tools(tools)
response = llm_with_tools.invoke(messages)
# We return a list, because this will get added to the existing list
return {"messages": [response]}
Python
복사
•
Agent 노드로 메시지가 전파될 때, 호출할 함수를 정의합니다.
•
bind_tools() 함수를 사용하여, 앞서 정의한 LLM 모델과 Tool를 바인딩합니다. 이를 통해, LLM이 자동으로 tool을 사용할 수 있도록 합니다.
연관성 라우팅 함수 정의
Retriever tool이 호출되어 문서를 샘플링 할 때, 과연 사용자의 질문과 관련성이 있는 문서인지 검증하는 함수입니다. LangChain에서 제공하는 evaluator를 통해 연관성을 계산하여 라우팅 방식을 결정합니다.
•
연관성 점수가 기준치 이하: 질문을 재생성할 수 있도록, rewrite 노드로 라우팅
•
연관성 점수가 기준치 이상: 답변을 생성할 수 있도록, generate 노드로 라우팅
hf_evaluator = load_evaluator("embedding_distance", embeddings=hf_embeddings)
def grade_documents(state: AgentState) -> Literal["generate", "rewrite"]:
"""
Determines whether the retrieved documents are relevant to the question.
Args:
state (messages): The current state
Returns:
str: A decision for whether the documents are relevant or not
"""
print("---CHECK RELEVANCE---")
docs = state['messages'][-1].content
question = state['messages'][0].content
scored_result = hf_evaluator.evaluate_strings(prediction=docs, reference=question)
score = scored_result['score']
if score < 0.5:
print("---DECISION: DOCS RELEVANT---")
return "답변 생성"
else:
print("---DECISION: DOCS NOT RELEVANT---")
print(score)
return "질문 재생성"
Python
복사
Rewrite 노드 설정
사용자의 의도에 부합하는 선에서, 질문을 재생성하는 역할을 수행합니다.
def rewrite(state: AgentState):
"""
Transform the query to produce a better question.
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---TRANSFORM QUERY---")
messages = state["messages"]
question = messages[0].content
msg = [
HumanMessage(
content=f""" \n
Look at the input and try to reason about the underlying semantic intent / meaning. \n
Here is the initial question:
\n ------- \n
{question}
\n ------- \n
Formulate an improved question: """,
)
]
# Grader
response = llm.invoke(messages)
return {"messages": [response]}
Python
복사
Generate 노드 설정
벡터 데이터베이스에서 제공 받은 문서를 참고하여, 사용자에게 답변을 제공합니다. 시스템 프롬프트를 통해, 답변 과정에서 지켜야 할 규칙들을 명시했습니다.
def generate(state: AgentState):
"""
Generate answer
Args:
state (messages): The current state
Returns:
dict: The updated state with re-phrased question
"""
print("---GENERATE---")
messages = state["messages"]
question = messages[0].content
last_message = messages[-1]
docs = last_message.content
# Prompt
prompt = PromptTemplate(
template="""
당신은 도움이 되고 정직한 AI 어시스턴트입니다.
주어진 컨텍스트를 사용하여 사용자의 질문에 답변해야 합니다.
다음 규칙을 따르세요:
1. 항상 한국어로 답변하세요.
2. 주어진 컨텍스트에 있는 정보만 사용하세요.
3. 컨텍스트에 없는 정보를 지어내지 마세요.
4. 가능한 간결하고 명확하게 답변하세요.
컨텍스트: {context}\n\n
사용자의 질문: {question}
""",
input_variables=["context", "question"],
)
# Chain
rag_chain = prompt | llm | StrOutputParser()
# Run
response = rag_chain.invoke({"context": docs, "question": question})
return {"messages": [response]}
Python
복사
답변 검증 라우팅 함수 정의
Qwen 모델의 경우, 다국어를 지원합니다. 간혹, 출력 문장에 중국어 기반 문자가 등장할 수 있습니다. 따라서, 중국 문자가 포함될 경우, 답변을 생성하도록 합니다.(generate 노드 호출)
def check_chinese(state) -> Literal["generate", "END"]:
"""
Determines whether the generated answer contains Chinese characters. If it does, it returns 'rewrite'.
Args:
state (dict): The current state
Returns:
str: A decision on whether the answer should be generated or rewritten.
"""
print("---CHECK FOR CHINESE CHARACTERS---")
generation = state["messages"][-1].content
# Check for the presence of Chinese characters using regex
def contains_chinese(text: str) -> bool:
return re.search(r'[\u4e00-\u9fff]', text) is not None
if contains_chinese(generation):
print("---DECISION: CHINESE CHARACTERS DETECTED---")
return "답변 재생성"
else:
print("---DECISION: NO CHINESE CHARACTERS DETECTED---")
return "대화 종료"
Python
복사
최종 Graph 객체 정의
앞서 정의한 노드들을 통해, 최종 graph를 정의합니다.
•
노드 추가
•
간선(edge) 추가 → 방향 설정
# Define a new graph
workflow = StateGraph(AgentState)
# Define the nodes we will cycle between
workflow.add_node("agent", agent) # agent
retrieve = ToolNode([retriever_tool])
workflow.add_node("retrieve", retrieve) # retrieval
workflow.add_node("rewrite", rewrite) # Re-writing the question
workflow.add_node(
"generate", generate
) # Generating a response after we know the documents are relevant
# Call agent node to decide to retrieve or not
workflow.add_edge(START, "agent")
# Decide whether to retrieve
workflow.add_conditional_edges(
source="agent",
# Assess agent decision
path=tools_condition,
path_map={
# Translate the condition outputs to nodes in our graph
"tools": "retrieve",
END: END,
},
)
# Edges taken after the `action` node is called.
workflow.add_conditional_edges(
source="retrieve",
# Assess agent decision
path=grade_documents,
path_map={
# Translate the condition outputs to nodes in our graph
"답변 생성": "generate",
"질문 재생성": "rewrite",
},
)
workflow.add_conditional_edges(
source="generate",
# Assess agent decision
path=check_chinese,
path_map={
# Translate the condition outputs to nodes in our graph
"답변 재생성": "generate",
"대화 종료": END,
},
)
workflow.add_edge("rewrite", "agent")
# Compile
graph = workflow.compile()
Python
복사
데모
이제, 실제로 AI Agent를 호출해볼까요?
%%time
import pprint
inputs = {
"messages": [
("user", "정책 금융의 2024년 지원 규모는 얼마나 되나요?"),
]
}
output = graph.invoke(inputs)
>>
---CALL AGENT---
---CHECK RELEVANCE---
---DECISION: DOCS RELEVANT---
---GENERATE---
---CHECK FOR CHINESE CHARACTERS---
---DECISION: NO CHINESE CHARACTERS DETECTED---
CPU times: user 129 ms, sys: 1.82 ms, total: 131 ms
Wall time: 2.17 s
Python
복사
사용자의 질문을 받고, 바로 대답할 수 없어서 Tool calling을 수행했네요
이에 따라, retrieve 노드에서 Document를 추출하고, 질문과의 연관성을 확인하는 과정을 거쳤습니다.
그 결과, DOCS RELEVANT 시그널을 통해, 연관성이 확보된 것을 확인할 수 있습니다.
이에 따라, LLM은 제공받은 Document를 참고하여 답변을 생성합니다.
마지막으로, 답변 검증 결과 중국어가 발견되지 않았으므로, 사용자에게 반환합니다.
전체 코드 실행 시간은 2.17초가 걸린 것을 확인할 수 있습니다.
output
>> {'messages': [HumanMessage(content='정책 금융의 2024년 지원 규모는 얼마나 되나요?', additional_kwargs={}, response_metadata={}, id='43c816a1-b423-48b4-935d-3a582f9dcf53'),
AIMessage(content='', additional_kwargs={'tool_calls': [{'id': 'chatcmpl-tool-45265127f913436d95929b8d25db63cc', 'function': {'arguments': '{"query": "2024\\ub144 \\uc815\\ucc45 \\uae08\\uc735 \\uc9c0\\uc6d0 \\uaddc\\ubaa8"}', 'name': 'retrieve_pdf_file'}, 'type': 'function'}], 'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 33, 'prompt_tokens': 209, 'total_tokens': 242, 'completion_tokens_details': None, 'prompt_tokens_details': None}, 'model_name': '/content/drive/MyDrive/LLM/ai_agent/Qwen2.5-3B-Instruct-GPTQ-Int4', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None}, id='run-d13cfc66-58fb-4c1c-94ff-d66dfc473ce8-0', tool_calls=[{'name': 'retrieve_pdf_file', 'args': {'query': '2024년 정책 금융 지원 규모'}, 'id': 'chatcmpl-tool-45265127f913436d95929b8d25db63cc', 'type': 'tool_call'}], usage_metadata={'input_tokens': 209, 'output_tokens': 33, 'total_tokens': 242, 'input_token_details': {}, 'output_token_details': {}}),
ToolMessage(content='경쟁력 확보를 위한 금융지원이 지속 추진 중임○정책금융기관의 혁신성장 분야 정책금융 공급규모는 2017년 240,787억 원에서 연평균 37.2% 증가하여 2021년 854,338억 원에 이르는 등 그 외연을 확장해나가고 있음○정책금융\n\n공급액 규모는 2021년 말 기준 16.9조 원으로 2017년 이후 연평균 39.2% 지속 증가하고 있음○ICT 산업의 공급액 규모 비중은 혁신성장 정책금융 총 공급 규모의 약 20% 수준임 * (‘17)18.7% → (’18)20.7% → (’19)18.5% → (’20)20.3% → (’21)19.8%\n\n(1.2)(1.9)(1.5)(1.7)(1.6)혁신성장 정책금융 총 공급액240,787 351,987 443,180 688,409 854,338 3. 정보통신 테마 혁신성장 정책금융 현황 및 관련 산업 동향▶(지원 현황) 정보통신 테마를 구성하는 기술분야별 정책금융 지원 현황\n\n기준으로, ‘9대 테마 – 46개 분야 – 296개 품목’으로 구성○정책금융기관의 혁신성장 정책금융 공급규모는 2017년 24.1조 원에서 2021년 85.4조 원으로 크게 증가하여 국내 산업 구조의 미래 산업으로의 전환을 충실히', name='retrieve_pdf_file', id='17918b82-e96b-493c-903c-3c09d3ab1135', tool_call_id='chatcmpl-tool-45265127f913436d95929b8d25db63cc'),
HumanMessage(content='2021년 기준으로 연평균 39.2% 증가한 상태에서 2024년까지 3년간 연평균 39.2%씩 증가한다면, 2024년의 정책금융 지원 규모는 약 110조 원을 넘을 것입니다. 하지만 실제 2024년의 정확한 지원 규모는 정부 정책과 경제 상황 등에 따라 다를 수 있습니다.', additional_kwargs={}, response_metadata={}, id='56f14b24-019d-49d9-9966-e27297704b69')]}
result = output['messages'][-1].content
pprint.pprint(result, indent=2, width=80, depth=None)
>>
('2021년 기준으로 연평균 39.2% 증가한 상태에서 2024년까지 3년간 연평균 39.2%씩 증가한다면, 2024년의 정책금융 지원 '
'규모는 약 110조 원을 넘을 것입니다. 하지만 실제 2024년의 정확한 지원 규모는 정부 정책과 경제 상황 등에 따라 다를 수 '
'있습니다.')
Python
복사
vllm 서버 구축을 하지 않고, 직접 로컬에 있는 모델을 사용하여 AI Agent 이용할 때, 전체 코드 실행 시간은 4.09초가 걸리더라구요!
확실히, LLM 모델을 서빙할 때는 vllm 등의 프레임워크를 도입하는 것이 도움이 되는 것 같습니다.
관련 코드 역시 아래에 첨부하였으니, 구현 방식과 결과 값을 비교해보세요!
정리
#### 작성 예정 ####
Reference
[Langchain-OpenAI]
[Serving LLM with vllm]
[Tool calling with Qwen]
[Serving LLM with vllm + OpenAI API]

[Making AI Agent using Langraph]