
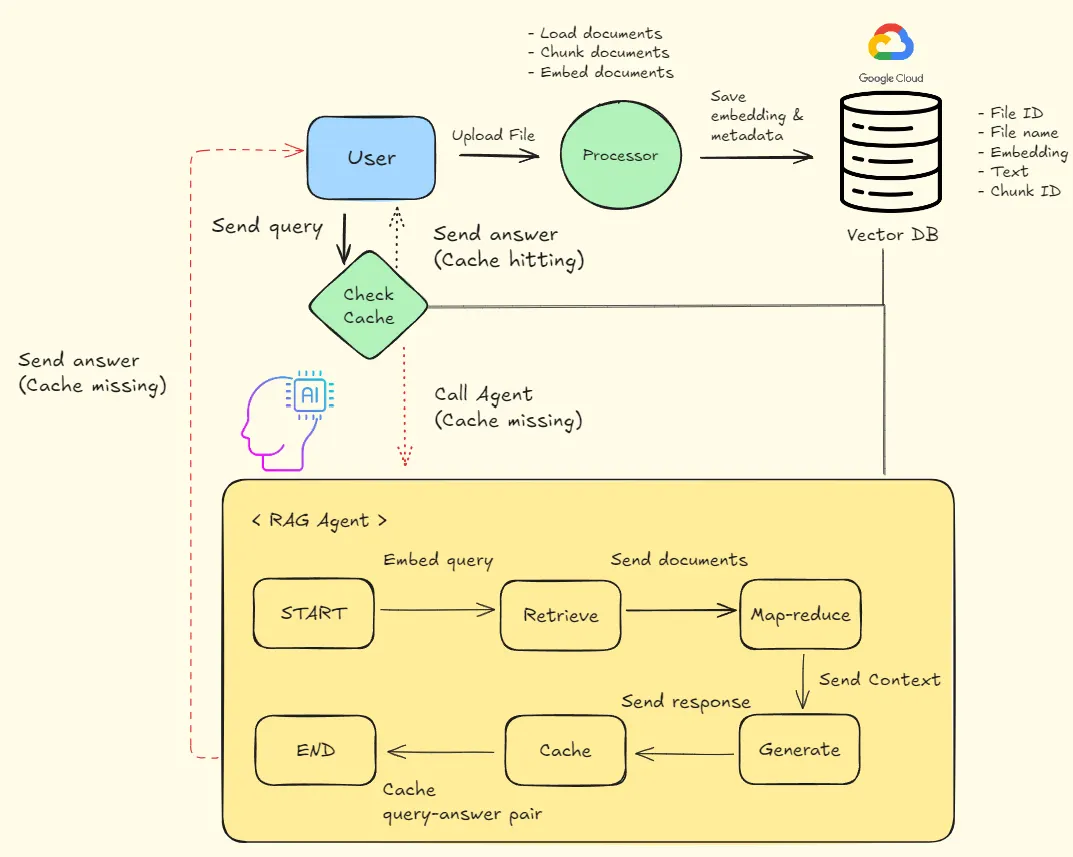
Workflow
전체 프로세스는 다음과 같습니다.
•
캐시 시스템
•
파일 전처리(Loader, Chunking, Embedding, Vector database)
•
RAG Agent
캐시 시스템 구축
도입 배경
사용자가 동일하거나 비슷한 질문을 반복할 수 있습니다.
따라서, 매번 RAG를 수행하는 것은 시간과 비용 측면에서 바람직하지 않습니다.
캐시를 활용하면 불필요한 리소스 낭비를 최소화 할 것으로 판단했습니다.
작동 방식
Step 1) 사용자의 질문(쿼리)을 임베딩한다.
Step 2) Vector DB에서 사용자의 쿼리와 의미적으로 가장 유사한 쿼리를 추출한다. (Semantic search)
Step 3) 쿼리 유사도가 일정 수준 이상일 때, 캐시가 적중한 것이다. 그 반대의 경우는 캐시 미스로 간주한다.
Step 4) 캐시가 적중한 경우, 사용자에게 캐시에 저장된 답변을 제공한다. 캐시 미스인 경우, RAG Agent를 호출한다.
고려 사항
유사도 측정 지표
임베딩 벡터 간 유사도 지표로서, 주로 아래와 같은 지표가 활용됩니다.
•
코사인 유사도(Cosine similarity)
•
유클리드 거리(Euclidean distance)
•
내적(Inner product) 값 사용
저는 유사도 측정 지표로서, 코사인 유사도를 활용하였습니다.
유클리드 거리 및 내적의 경우, 연산 결과의 범위가 실수 전체입니다. 따라서, 결과 값에 따른 해석이 모호할 수 있다고 판단했습니다.
임베딩 모델 선택
메인 코드를 참고하여 아래와 같이 크게 두 모델을 적용해봤습니다.
•
HCXEmbeddings (HyperCLOVA)
•
OpenAIEmbeddings (OpenAI)
각 모델을 사용하여, 문장 쌍(pair)의 코사인 유사도를 측정하였습니다.

임베딩 모델 별 코사인 유사도 측정 예시
문장 1: 오늘 서울의 날씨는 어떤가요?
문장 2: 떡볶이 레시피를 알려주세요.
HCXEmbeddings >> 0.99
OpenAIEmbeddings >> 0.72
임베딩 모델 | 평균(30회 측정) | 표준편차(30회 측정) |
HCXEmbeddings | 0.967 | 0.013 |
OpenAIEmbeddings | 0.703 | 0.028 |
OpenAIEmbeddings 임베딩 모델이, 의미가 다른 두 문장의 구분을 더 잘하는 것으로 판단했습니다.
따라서, 이번 시간에는 해당 임베딩 모델을 사용하였습니다.
캐시 데이터베이스 설정 및 CRUD 쿼리 (또는 코드)
파일 전처리
크게 다음과 같은 컴포넌트로 구성했습니다.
•
Data loader
•
Text splitter
•
Embedding
•
Vector database
Data loader
Data loader를 선택할 때, 다음과 같은 기준을 사용했습니다.
•
문서를 원래 형태로 잘 가져오는지? > 한글 또는 특수 문자의 경우, 인코딩 문제로 인해 깨 수 있음
•
문서의 메타데이터 제공 범위 > 페이지 번호, chunk 번호, 삽입(또는 수정) 일자 등
•
문서를 읽는 속도
크게 다음과 같은 후보군을 선정했습니다.
•
fitz: 각 페이지를 읽는 속도가 빠른 편, 그러나 페이지 번호를 제외한 메타데이터 미제공
•
PyPDFLoader: 한글 인코딩, 페이지 읽는 속도 준수 + 메타데이터 (소스, page 번호) 제공
•
UnstructuredPDFLoader: 방대한 메타데이터 제공(좌표, 카테고리, 파일 타입 등), 그러나 읽는 속도가 상대적으로 느림
•
PDFPlumber: 한글 인코딩 능력 우수, 다양한 메타데이터 제공(수정 일자, 작성자 등), 그러나 읽는 속도가 느린 편
이 중에서, 저는 다음과 같은 이유로 PDFPlumber를 최종 loader로 선정했습니다.
•
한글 깨짐 현상이 거의 없음
•
표 안에 있는 텍스트를 상대적으로 잘 추출함
•
문서 삽입(수정) 일자 정보 제공함 >> 추후, 캐싱 시스템 개선에 필요하다고 판단함
Text splitter
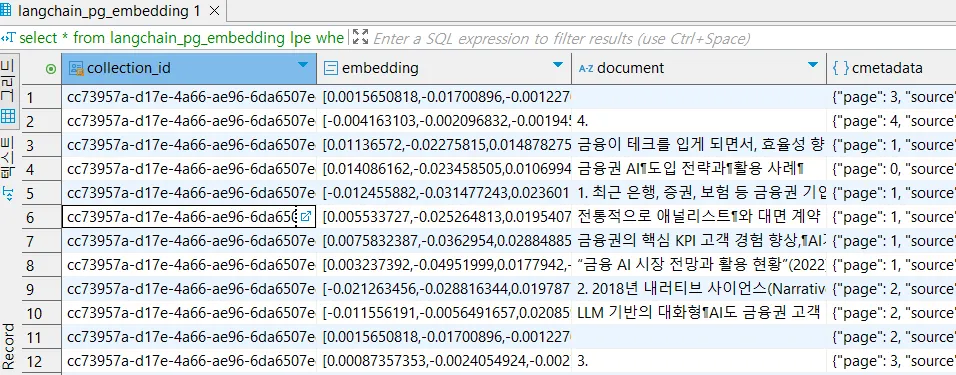
Character 또는 Recursive Splitter의 경우, 간단하게 사용될 수 있습니다. 하지만, 분절된 Document가 의미있는 텍스트를 가지지 못하는 경우가 많습니다. 맥락에 관계없이, document를 나누기 때문입니다.
•
ex: Retrieval Augmented Generation >> [’Retrieval’, ‘Augmented Generation’]
아래 document 컬럼을 보시면, 비어있거나 항목만 존재하는 document가 다수 있는 것을 확인했습니다.
저는 앞선 문제점을 해결하기 위하여, Langchain에서 제공하는 SemanticChunker 클래스를 사용하였습니다.
SemanticChunker 클래스는 LLM 모델을 활용하여, 각 document 집합(chunk로 지칭)의 임베딩 벡터를 구합니다. 그 다음, chunk 간 임베딩 유사도가 기준을 충족했을 때, 이 chunk들을 하나의 그룹으로 묶습니다.
자세한 동작 원리를 알고 싶으시면, ‘SemanticChunk 클래스의 자세한 동작 원리’ 섹션을 확인해주세요!
Chunking 예시 >> 혁신성장 정책금융 동향: ICT 산업을 중심으로 (한국신용정보원)
(Optional) SemanticChunker 클래스의 자세한 동작 원리 (Langchain 코드 분석 기반)
(Optional) 코드 리팩토링을 통한 chunking 속도 개선 > SemanticChunker 클래스
Embedding
벡터 데이터베이스에 사용할 임베딩으로서, 앞서 설명드린 OpenAIEmbedding을 활용하였습니다.
임베딩 모델 정의 코드
Vector database
main 코드에서 사용한 PGVector 데이터베이스를 사용하였습니다.
또한 구현체는 Langchain에서 제공하는 PGVector 클래스를 활용했습니다.
본 과제에서, Vector DB의 핵심 용도는 다음과 같습니다.
•
Document에 대한 임베딩 저장
•
임베딩 간 유사도 계산 >> RAG Agent에 컨텍스트를 제공하기 위함
◦
사용자의 쿼리 임베딩 벡터를 기준으로, 가장 유사한 K개의 Document 추출
◦
K개의 document를 컨텍스트로 제공
Vector database 클래스 구현체
임베딩 간 유사도 측정 코드
RAG Agent 구축
본 과제에서는 LangGraph를 이용하여, RAG Agent에 대한 그래프를 구축했습니다. 이때, 그래프를 구성하는 노드 목록은 아래와 같습니다 (실행 순서에 맞춤).
•
Retrieve: 사용자의 쿼리와 의미적으로 가장 유사한 K개의 Document를 추출
•
Map-reduce: K개의 Document를 하나의 컨텍스트로 요약
•
Generate: 사용자의 쿼리와 컨텍스트를 활용하여, 최종 답변 생성
•
Cache: 사용자의 쿼리와 최종 답변을 캐시 데이터베이스에 저장
Graph status
각 노드에 대한 구체적 설명에 앞서, 그래프 상태에 대해 언급하겠습니다.
from typing import (
Optional,
TypedDict,
List
)
from langchain_core.documents import Document
class GraphState(TypedDict):
query: str
query_embedding: List[float]
retrived_documents: Optional[List[Document]]
context: Optional[str]
response: Optional[str]
Python
복사
총 5가지의 변수를 통해 그래프의 상태를 정의했습니다. 각 변수에 대한 설명은 다음과 같습니다.
•
query: 사용자의 질문를 의미합니다.
•
query_embedding: 쿼리에 대한 임베딩 벡터입니다. 해당 벡터와 의미적으로 유사한 다큐먼트들을 추출합니다.
•
retrived_docments: 벡터 DB로부터 추출된 다큐먼트 집합입니다. 해당 데이터를 활용하여, map-reduce 과정을 수행합니다.
•
context: map-reduce 과정을 통해, 요약된 document의 컨텐츠를 의미합니다. LLM은 해당 컨텍스트를 참고하여, 사용자의 질문에 맞는 답변을 생성합니다.
•
response: LLM이 최종적으로 생성한 답변을 의미합니다.
Retrieve
사용자의 쿼리를 참고하여, 벡터 DB에서 의미적으로 가장 유사한 K개의 Document 정보를 추출하는 과정입니다. 자세한 과정은 앞서 언급한 ‘Vector database’ 파트로 갈음하겠습니다.
Map-reduce
Retrieve 노드를 통해 추출한 K개의 다큐먼트를 요약하는 과정입니다.
방대한 컨텐츠 중 사용자의 질문과 관련된 핵심 파트를 추출하면, LLM이 답변을 효과적으로 생성할 수 있을 것으로 판단했습니다. 무엇보다, 처음 구현해보는 기능이라 한 번 해보고 싶었습니다.
Map-reduce 과정은 다음과 같이 크게 두 가지 단계로 수행됩니다.
•
step 1) Map: 각 Document의 내용을 요약하는 단계입니다. 이후, K개의 요약된 다큐먼트를 하나로 합칩니다.
•
step 2) Reduce: 합쳐진 다큐먼트를 다시 한 번 요약하는 단계입니다.
Map-reduce 코드
Map-reduce 프롬프트
Generate
Map-reduce 노드에서 제공 받은 컨텍스트를 사용하여, 사용자의 질문에 대한 답변을 생성하는 과정을 수행합니다.
답변 생성 과정
답변 생성 프롬프트
Generate 노드 코드 (LLM side)
FastAPI 라우터 코드 (answer 라우터)
추후 개선 사항
데이터의 최신성
RAG의 특성 상, 주기적으로 새로운 문서가 데이터베이스에 추가됩니다. 이에 따라, 동일한 질문을 던졌을 때, 갱신된 답변을 제공할 수 있어야합니다.
하지만, 기존에 구현한 시스템은 캐시 데이터를 업데이트하는 로직이 존재하지 않습니다.
따라서, 추후 캐시 테이블을 업데이트하는 로직을 반영하고자 합니다.
•
주기적 배치 처리: 일정 주기마다, 캐시에 저장된 Query - answer pair를 업데이트한다. > 데이터가 많아질수록 LLM calling 횟수가 많아질 수 있다 > 비용 및 실행 시간 측면에서 부담이 클 수 있다.
•
LRU(Least Recently Used Algorithm): 캐시를 저장할 DB의 용량을 제한할 수 있다 > But, 자주 사용되는 쿼리에 대한 답변은 계속 갱신되지 못할 가능성이 높다.
•
TTL(Time-To-Live): 사용자가 날린 쿼리의 유효 기간을 판단하여, 만료가 된 쿼리에 대해서만 데이터를 업데이트한다 > 주기적 배치 처리 및 LRU의 단점을 어느정도 보완한 방법이라고 생각합니다.
다양한 파일 확장자 지원
현재 PDF 확장자를 가진 파일에 한하여, RAG 에이전트를 적용했습니다.
하지만, 실제 서비스 환경에서는 txt, excel, pdf 등 다양한 종류의 파일을 처리할 수 있어야 합니다.
따라서, 추후에는 범용적으로 파일을 처리할 수 있는 파이프라인을 구축할 예정입니다.
•
Data Loader
•
Text splitter
•
Embedding
•
Vector Database
RAG 답변 검증과 개선
LLM이 컨텍스트를 이용해 답변을 생성했지만, 사용자의 질문에 적합한 것인지 확인할 필요가 있습니다.
그렇지 못할 경우, 답변을 개선시킬 수 있는 방법을 찾아 적용해야합니다.
•
쿼리 - 답변 pair 검증 방법 정의
◦
Langchain에서 제공하는 evaluator를 사용: 문장(또는 chunk) 간 다양한 비교 방법 및 측정 지표를 제공합니다. 따라서, 다양한 검증 방법을 손쉽게 사용할 수 있습니다.
▪
비교 방법: Exact match, Embedding distance, Context Question & Answering 등
▪
측정 지표: Cosine, Euclidean, Hamming, Manhattan, and Chebyshev distance
◦
LLM을 활용하여 답변 검증: 평가 방법을 기술한 프롬프트를 LLM에게 제공 >> LLM은 평가 기준에 따라, 답변의 퀄리티를 측정
•
답변 개선 방법 정의
◦
답변 검증 기준을 충족시키지 못할 때, 사용자의 질문 의도에 맞도록 답변을 개선하는 과정이 필요합니다.
▪
Self-evaluation, Web search 등
질문 리스트
•
AI 분류 프레임워크에 대해 설명해주세요.
•
AI 프레임워크를 성능 단계별로 설명해줘
•
금융권에서 RAG가 어떻게 활용되고 있나요?
•
업무 자동화에 대해 설명해줘.
•
생성형 AI 콘텐츠가 언제 삭제될 수 있나요?
•
생성 AI 콘텐츠가 삭제될 수 있는 경우를 설명해주세요.
•
생성형 AI는 우리에게 어떤 도움을 줄 수 있나요?
•
기술분야별 정책금융 공급 현황을 설명해줘.
•
2024년 AI 주요 행사 일정을 알려주세요.