
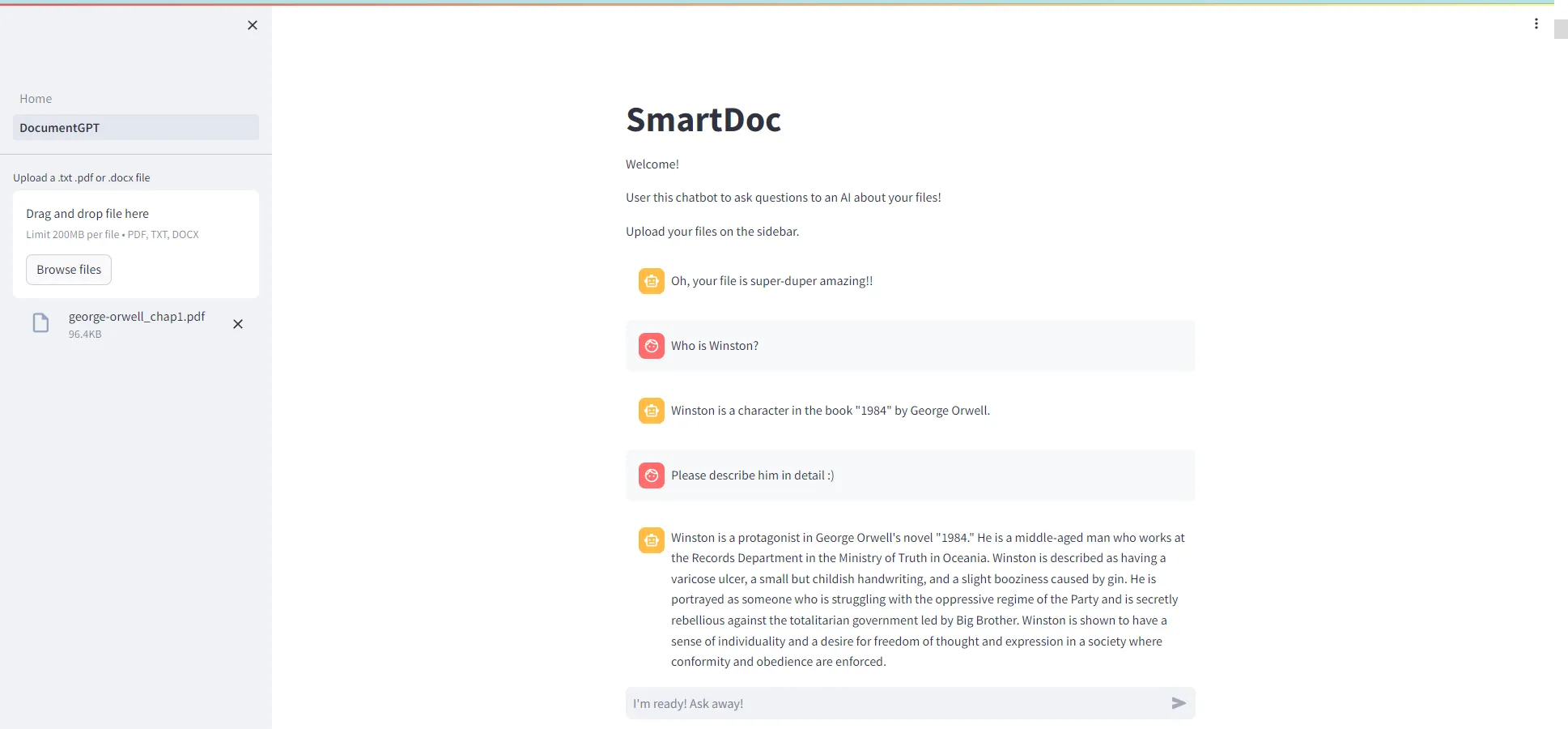
요즘 LLM의 매력에 푹 빠져서, 오랜만에 노마드 코더님의 강의를 듣고 있는데요
문서 정보를 제공해주는 챗봇 애플리케이션을 제작하는 과정이 재밌으면서, 정말 배울 점이 많아 이 곳에 정리하려고 합니다. 논문 내용을 정리하거나, 막히는 부분이 있을 때 ChatGPT를 활용하는데, 서비스를 클론 코딩을 해볼 수 있어 정말 좋았습니다!
목표는 챗봇 애플리케이션을 만드는 것이며, 챗봇은 주어진 문서에 대한 정보를 제공하는 역할을 수행합니다. 이때, 웹 애플리케이션 제작을 위해 Streamlit 프레임워크를 사용하였습니다. 또한, Langchain을 통해, LLM 기반 챗봇 구현을 수행했습니다.
전체 코드와 데모 영상은 아래 깃허브 링크에 있으니, 참고하시면 좋을 것 같습니다!
챗봇 애플리케이션을 위해 구현해야 할 요소는 크게 다음과 같습니다.
To-do list
1. 사용자로부터 문서를 제공 받을 위젯 생성
2. 챗봇을 위한 LLM 모델 생성
3. RAG(Retrieval Augmented Generation) 구현
4. 프롬프트 생성
5. 대화 내용을 출력(display)
문서 업로드 위젯 생성
사용자가 문서를 챗봇에 보내는 방법 및 업로드 후에 애플리케이션이 수행할 동작을 정의합니다.
먼저, Streamlit 프레임워크의 file_uploader() 함수를 통해 위젯을 생성하고, 파일을 입력 받을 수 있습니다. 이때, 사이드 바(sidebar)에 위젯을 배치하는 것이 깔끔한 것 같아, 해당 사항을 반영했습니다.
# pages/DocumentGPT.py
import streamlit as st
from streamlit.runtime.uploaded_file_manager import UploadedFile
# embed file uploader inside sidebar
with st.sidebar:
file: UploadedFile = st.file_uploader(
label="Upload a .txt .pdf or .docx file",
type=["pdf", "txt", "docx"]
)
Python
복사
이때, 챗봇에게 문서를 전달하는 목적을 생각해봅시다!
바로, RAG를 통해 챗봇이 문서를 이해하고, 사용자에게 문서의 정보를 제공하려는 것이죠 :)
따라서, 챗봇은 문서를 제공받은 다음, RAG 기반 응답을 위해 아래의 동작을 수행해야 합니다.
파일 업로드 후에 애플리케이션이 수행할 동작
•
File Loader와 Spliter 정의 → 예를 들어, Spliter는 파일을 문장 혹은 문단 단위로 쪼갤 수 있습니다.
•
캐싱 기능을 포함한 임베딩(Embedding) 모델 정의
•
임베딩 정보를 저장할 벡터 스토어(Vector store) 정의
•
Retriever 정의 → 사용자의 질문(query)과 유사한 정보를 벡터 스토어에서 추출하는 객체입니다.
이때, 한 가지를 추가적으로 고려해야합니다. 바로, Streamlit의 Data flow입니다!
Streamlit은 웹 애플리케이션에 추가적인 정보(채팅 내역, 파일 등)가 입력될 때마다, 애플리케이션 코드를 처음부터 끝까지 다시 실행하는 특징이 있습니다.
이때, RAG 기반 응답을 위해 필요한 컴포넌트를 매번 정의하는 것은 비효율적인 행위입니다. File Loader, Document Splitter, Embedding 모델, 벡터 스토어 및 Retriever 모두 애플리케이션이 실행되면 값이 바뀌지 않는 객체이기 때문입니다!
이를 위해, Streamlit에서는 cache_resource 데코레이터(@cache_resource)를 제공합니다. 해당 데코레이터를 적용한 함수는 반복적으로 실행되지 않습니다. 따라서, 파일 업로드 후에 애플리케이션이 수행할 동작을 embed_file()이라는 함수로 정의하고, cache_resource 데코레이터를 적용하겠습니다.
# src/cache_resource.py
from streamlit.runtime.uploaded_file_manager import UploadedFile
from langchain.document_loaders import UnstructuredFileLoader
from langchain.text_splitter import CharacterTextSplitter
from langchain.embeddings import OpenAIEmbeddings, CacheBackedEmbeddings
from langchain.storage import LocalFileStore
from langchain.vectorstores.chroma import Chroma
from langchain.schema.vectorstore import VectorStoreRetriever
@st.cache_resource(show_spinner="Embedding file...")
def embed_file(file: UploadedFile) -> VectorStoreRetriever:
# 위젯을 통해 파일을 읽어들입니다.
file_content = file.read()
file_path = f"./.cache/files/{file.name}"
with open(file_path, "wb") as f:
f.write(file_content)
# Document Loader와 splitter를 정의합니다.
splitter = CharacterTextSplitter.from_tiktoken_encoder(
separator="\n",
chunk_size=500,
chunk_overlap=100
)
loader = UnstructuredFileLoader(file_path)
docs = loader.load_and_split(text_splitter=splitter)
# 캐시 기능을 포함한 임베딩 객체를 정의합니다.
embeddings = OpenAIEmbeddings()
cache_dir = LocalFileStore(f"./.cache/embeddings/{file.name}")
cached_embeddings = CacheBackedEmbeddings.from_bytes_store(
underlying_embeddings=embeddings,
document_embedding_cache=cache_dir
)
# 벡터 스토어와 Retriever를 정의합니다.
vectorstore = Chroma.from_documents(
documents=docs,
embedding=cached_embeddings
)
retriever = vectorstore.as_retriever()
# Retriever 객체를 반환합니다.
return retriever
Python
복사
챗봇을 위한 LLM 모델 생성
저는 채팅을 위한 LLM 모델과, 대화 내용을 저장하기 위한 LLM 모델을 분리하여 생성했습니다.
이렇게 하지 않을 경우, 챗봇이 사용자에게 답변을 제공할 때, 이전에 답변했던 내용을 중첩하여 제공하더라구요(정확한 이유는 지금도 찾아보고 있습니다.)
LLM 모델을 생성하는 과정은 애플리케이션 실행 동안 딱 한 번만 수행하면 됩니다. 따라서, cache_resource 데코레이터를 사용하여 함수를 구현해봅시다.
# src/cache_resource.py
from typing import Union
import streamlit as st
from streamlit.delta_generator import DeltaGenerator
from langchain.chat_models import ChatOpenAI
from langchain.chat_models.base import BaseChatModel
from langchain.callbacks.base import BaseCallbackHandler
from langchain.memory import ConversationSummaryBufferMemory
@st.cache_resource
def initialize_llm(mem_type: Union[str] = None) -> Union[BaseChatModel]:
if mem_type == 'chat':
class ChatCallbackHandler(BaseCallbackHandler):
message = ""
def on_llm_start(self, *args, **kwargs):
self.message_box: DeltaGenerator = st.empty()
def on_llm_end(self, *args, **kwargs):
save_message(self.message, "ai")
self.message = ""
def on_llm_new_token(self, token: str, *args, **kwargs):
self.message += token
self.message_box.markdown(self.message)
callbacks = [ChatCallbackHandler()]
else: # mem_type == memory
callbacks = []
return ChatOpenAI(
temperature=0.2,
streaming=True,
callbacks=callbacks
)
Python
복사
채팅 용도(chat)와 대화 기록 저장(memory)용도를 구분하여, 사전 학습된 LLM 모델을 호출하는 함수를 구성하였습니다.
이때, 채팅용 LLM 모델을 로드할 때, Callback handler 인스턴스를 생성하여 인자로 제공한 것을 확인하실 수 있습니다! 이것은, 챗봇의 답변 내용을 스트림 형식으로 화면에 출력하기 위함입니다. ChatGPT을 예로 들면, 질문에 대한 응답을 제공할 때, 모든 내용을 한 번에 출력하는 것이 아니라, 스트리밍을 통해 응답을 화면에 제공하지요
on_llm_start, on_llm_end, on_llm_new_token 함수는 모두 Langchain에서 기본적으로 제공하는 함수이며, 이를 제 사용 목적에 맞게 커스터마이징 한 것입니다.
함수 커스터마이징
on_llm_start: LLM 모델의 답변 시작 타이밍에 실행되는 함수입니다. 응답 내용을 화면에 출력하기 위한 컨테이너(Container) 객체를 생성하는 역할을 담당합니다.
on_llm_end: LLM 모델의 답변 종료 타이밍에 실행되는 함수입니다. 응답 내용을 별도의 공간에 저장하는 역할을 수행합니다. → 챗봇이 대화 맥락을 기억하여 답변을 생성할 수 있도록 함
on_llm_new_token: LLM 모델이 답변을 생성할 때마다 실행되는 함수입니다. 응답 내용을 토큰 단위로 스트리밍하여 화면에 보여질 수 있도록 합니다.
프롬프트 구성
사용자에 의도에 따라, 챗봇이 응답을 하기 위해서는 프롬프트를 올바르게 구성하는 과정이 필수입니다.
프롬프트를 구성하는 컴포넌트는 다음과 같습니다.
•
System: AI가 답변 생성 시, 준수해야 할 규칙을 명시
•
Context: AI가 답변 생성 시 참고할 Document 내용을 명시
•
Message Placeholder: AI가 이전 대화 내용을 고려하여 답변을 생성할 수 있도록 생성한 공간
•
Human: 질문을 하는 사용자
또한, 이를 반영한 코드는 아래와 같습니다.
# pages/DocumentGPT.py
from langchain.prompts import MessagesPlaceholder
prompt = ChatPromptTemplate.from_messages(
messages=[
("system",
"""
Answer the question using ONLY the following context and chat history.
If you don't know the answer, just say you don't know.
Don't make anything up.
Context: {context}
"""),
("human", "-" * 30),
MessagesPlaceholder(variable_name="chat_history"),
("human", "{question}"),
]
)
Python
복사
System으로 하여금, 대화 기록과 주어진 Context 정보만을 이용하여 답변을 제공하라는 명령을 내린 것을 확인하실 수 있습니다. 또한, Message Placeholder는 별도의 메모리에서 chat_history라는 key를 통해 대화 기록을 가져올 수 있습니다.
방금, Message Placeholder를 위해서는 별도의 메모리가 필요하다고 했는데요. 이를 위해, 메모리 객체를 생성하는 함수를 정의합시다. 이 과정 또한, 애플리케이션 동작 중 한 번만 실행하면 되므로, cache_resource 데코레이터를 적용합니다. Langchain에서 제공하는 ConversationSummaryBufferMemory 클래스를 통해 다음 기능을 활용해봅시다.
•
이전 대화 내용을 요약하여 메모리에 저장 → 토큰 수를 절약하기 위함
•
대화 내용을 저장할 공간(memory_key parameter)를 지정 → chat_history라는 공간에 저장
# src/cache_resource.py
import streamlit as st
from langchain.chat_models.base import BaseChatModel
from langchain.memory import ConversationSummaryBufferMemory
@st.cache_resource
def initialize_memory(_llm: BaseChatModel) -> ConversationSummaryBufferMemory:
return ConversationSummaryBufferMemory(
llm=_llm,
return_messages=True,
max_token_limit=200,
memory_key='chat_history'
)
Python
복사
RAG 구현
해당 파트에서는 RAG 구현을 위해 다음과 같은 사항을 고려했습니다.
•
1번: RAG 파이프라인을 통해, 챗봇의 답변 생성을 위한 Context을 생성하는 방법
•
2번: 메모리에서 이전 대화 기록을 추출하는 방법
•
3번: Context와 이전 대화 기록을 담은 프롬프트 정보를 챗봇에 전달하는 체인 생성
3번 과정을 생성하기 위해서는, 1번 및 2번 과정이 수행되어야 합니다. 프롬프트가 Context와 이전 대화 기록을 포함하고 있기 때문입니다. 정리하자면, 전체적인 실행 순서는 다음과 같습니다.
1번 & 2번(병렬 수행) → 3번 과정 수행
이를 표현하기 위하여, 저는 Langchain에서 제공하는 LCEL(Langchain Expression Language)를 활용하였습니다. LCEL에서는 리눅스와 동일하게 | 기호를 사용하여, 파이프라인을 생성할 수 있습니다. 이를 반영하여, 1~3번 과정을 표현한 chain을 다음과 같이 구현하였습니다.
# pages/DocumentGPT.py
from langchain.schema.runnable import RunnableLambda, RunnablePassthrough
# initialize LLM
llm_for_chat = initialize_llm(mem_type='chat')
llm_for_memory = initialize_llm()
# make prompt
prompt = ...
retriever: VectorStoreRetriever = embed_file(file)
# 3번 과정 수행
chain = {
"context": retriever | RunnableLambda(func=format_documents), # 1번 과정 수행
"chat_history": RunnableLambda(func=load_memory), # 2번 과정 수행
"question": RunnablePassthrough()
} | prompt | llm_for_chat
Python
복사
딕셔너리에 포함된 context, chat_history, question key에 해당하는 value를 프롬프트에 전달하고, 모든 값이 반영된 프롬프트를 다시 챗봇에 넘겨주는 구조입니다.
이때, 딕셔너리 내부에서도 체이닝(파이프라인) 기능을 사용한 것을 확인하실 수 있습니다.
딕셔너리 내부 체이닝 동작 설명
1. context: 일차적으로, Retriever 객체를 통해 사용자의 질문과 유사한 정보를 Vector store에서 검색합니다. 이때, 검색 결과를 Document의 집합으로 반환합니다. 이 정보를 RunnableLambda 함수에 넘겨주고, 단일 문자열로 변환하는 작업을 수행합니다.
전체 과정 정리
이제, 챗봇의 전체 동작 과정을 다음과 같이 정리할 수 있습니다.
•
사용자는 채팅에 필요한 문서(Document)를 업로드한다.
•
애플리케이션은 채팅에 필요한 리소스(LLM 모델, 메모리, 벡터 스토어 등)을 생성한다.
•
사용자는 채팅창을 통해 질문(question)을 입력한다.
•
애플리케이션 내부에서 chain.invoke(question) 함수를 호출하여, chain에 질문을 전달한다.
•
chain은 전달된 질문을 바탕으로, context를 생성하고 프롬프트에 넘겨준다. 이때, 이전 대화 기록도 프롬프트에 함께 반영한다.
•
chain에 의해, 프롬프트는 다시 챗봇에 넘어가게 되고, 챗봇은 주어진 프롬프트를 분석하여, 사용자 질문에 적합한 대답을 제공한다.
마치며
이번 시간에는, Streamlit과 Langchain 기반 문서 정보 제공 애플리케이션을 제작하고, 세부 사항을 정리하는 시간을 가졌습니다. 기회가 된다면, 클라우드 벡터 스토어를 활용하여 실제 서비스로 만들고 싶은 생각이 드네요
또한, 이번에는 RAG 구현 과정에서, Stuff 방식을 통해, 단순하게 모든 context를 하나로 합치는 작업을 수행했는데요. Map Reduce, Map re-rank, Refine 등 다양한 방식을 사용하여, 생성된 답변을 비교하는 것도 의미가 있을 것 같습니다. 마지막으로, 답변 생성 시간을 줄이기 위해서, 어떤 방법을 사용할 지 고민해보는 것도 남아있네요!
서비스를 만들기 위해서는 정말 고민해야 할 사항이 많다는 것을 다시 한 번 느끼고 갑니다!!
감사합니다.
그럼 안녕