

여러분 오늘도 좋은 하루입니다!
이번에는 ML 실험 설정을 간편하게 해주는 Hydra에 대해 다루어볼까 합니다
Hydra와 관련한 주제는 크게 세 가지 섹션으로 구성했어요
이번 시간은 첫 번째 주제로서, 제가 Hydra를 사용하게 된 이유와 미니 프로젝트 개요에 대해 살펴보도록 할게요
ML 기반 실험 관리의 어려움
석사 과정 당시, 대조 학습 방법을 추천 시스템에 적용하여 제품 추천 다양성을 증가시키는 연구를 수행한 적이 있습니다. 실제 연구에 사용하였던 설정 파일과 모델 학습 코드의 템플릿을 같이 확인해봅시다!
<설정 파일>
# config.yaml
learning_rate: 0.001 # learning rate for model
dropout_rate: 0.1 # dropout rate for model
lambda_for_cl: 0.1 # control loss for encoder model(range: 0 ~ 1, allow float type)
substitution_rate: 0.3 # ratio for item substitution in batch
masking_rate: 0.3 # ratio for item masking in batch
cropping_rate: 0.3 # ratio for item cropping in batch
batch_size: 256
sequence_len: 1 # if run_mode == 'diversity' you should use 1, else using 30 will be good
embedding_dim: 128 # embedding size
early_stop_patience: 20 # control early stopping steps
warmup_steps: 10000 # control warmup steps for learning rate scheduling
epochs: 200
clip_norm: 5.0 # gradient clipping norm
log_interval: 10 # interval for logging for loguru and wandb
temperature: 0.1 # temperature for NT-Xent Loss
try_num: '9' # experiment number
run_mode: 'test' # running mode for main.py: ['train', 'test', 'diversity']
data_type: 'RentTheRunway' # 'RentTheRunway'
train_type: 'NCF' # Model which you want to train: ['CL', 'REC', 'ONLY_REC', 'NCF']
aug_mode: 'substitute' # Item augmentaion mode: ['substitute', 'crop', 'mask']
rec_num_dense_layer: 2
model_trainable: False # True, False
k: 20 # top-K item
sparsity: 0.5 # transaction count sparsity for checking diversity
YAML
복사
<모델 학습 샘플 코드>
# train.py (Templete code)
from omegaconf import OmegaConf
# Duck typing for accessing dataclass variable
def load_config(path: str) -> Cfg:
schema = OmegaConf.structured(Cfg())
# duck typing
config: Cfg = OmegaConf.merge(schema, OmegaConf.load(path))
return config
# load config
config = load_config("config.yaml")
# load dataset
dataset = load_dataset(config)
# load dataloader
dataloader = load_dataloader(config)
# initialize model
model = Model(config)
# train model
model.train(dataset, dataloader, model)
Python
복사
코드를 작성할 당시에는 미숙한 부분이 많아, 실험 목표를 달성한 것에 만족하고 넘어갔습니다.
하지만, 추후 코드 리뷰를 하면서 실험 설정과 관련하여 코드를 수정할 곳이 매우 많다는 사실을 알게 되었어요
그 중에서, 핵심 사항은 다음과 같이 세 가지로 추렸습니다
1.
설정의 구조화
•
현재 config.yaml 파일은 실험 설정과 관련한 모든 파라미터의 정보를 포함하고 있습니다.
◦
실험 번호, 실험 종류, 데이터 종류 등의 메타 정보
◦
모델 파라미터
◦
모델 학습 파라미터
•
실제 ML 실험에서는 실험 버전 관리, 모델 초기화, 모델 학습 등 각 컴포넌트가 서로 다른 역할을 수행하며, 독립적으로 존재합니다.
•
하지만, 본 설정 파일은 위 특성을 무시한 채 모든 컴포넌트 정보를 한 곳에 배치하였습니다.
•
이 상태로 프로젝트의 규모가 커진다면, 현재까지 정의한 파라미터와 앞으로 추가해야 할 파라미터 대상을 인지하기 힘들어집니다.
2.
설정의 자동화
•
•
따라서, 실험 방식을 변경할 때 매번 config.yaml 파일에 존재하는 값을 사용자가 수동으로 변경해야 합니다.
•
그러므로, 실험 셋업 과정에 필요한 시간이 매우 많이 소모됩니다. 또한, 동일 시간 내에 수행할 수 있는 실험 횟수가 매우 제한적입니다.
3.
설정의 오류 가능성
•
config.yaml 파일 내에 존재하는 파라미터는 실수, 정수, 문자열 등 다양한 종류의 값을 가질 수 있습니다.
•
실제 실험 단계에서는 각 파라미터 값에 대하여 적합한 자료형이 있습니다.
◦
Learning rate → float
◦
Batch size → int
◦
etc
•
하지만, 현재는 파라미터 값에 대한 자료형 검사를 담당하는 코드가 존재하지 않습니다. 따라서, 코드의 안전성에 문제가 발생할 수 있습니다.
◦
Learning rate = “0.1”
◦
Batch size = 99.5
Hydra를 사용해보자
이에, 설정의 구조화/자동화 및 오류 가능성에 대한 문제를 개선할 수 있는 방법을 생각해보았습니다. 그 과정에서 저는 Hydra의 존재를 알게 되었고, 위 세 가지 문제를 해결해줄 수 있는 적임자라고 판단하였습니다
1.
설정의 구조화
•
•
예시로, 하나의 ML 실험에 대하여 다음과 같이 설정을 구조화할 수 있습니다.
◦
풀고자 하는 문제 종류
◦
문제를 해결하기 위한 모델
◦
모델 학습 및 평가에 사용할 데이터
◦
미니 배치 학습을 위한 데이터 로더
•
이와 관련하여, 자세한 설명은 ‘프로젝트 개요’ 파트에서 설명 드리겠습니다.
2.
설정의 자동화
•
Hydra를 사용하면, 런타임 단계에서 실험에 필요한 설정 값들을 자동으로 import 할 수 있습니다.
•
이때, 일부 설정 값만 변경하여 실험을 진행할 수 있습니다. Hydra는 CLI 인터페이스를 통해, 간단하게 설정 값을 변경할 수 있도록 도와줍니다.
◦
예시: 배치 사이즈를 128로, 최적화 알고리즘으로서 Adam optimizer를 사용하고 싶은 경우
python train.py data_module.batch_size=128 task/optimizer=adam
Python
복사
•
이에 따라, 실험 준비 과정에 필요한 시간을 큰 폭으로 줄일 수 있습니다.
3.
설정의 오류 가능성
•
•
이를 통해, 파라미터에 대한 정적 타입 검사 또는 런타임 타입 검사를 수행할 수 있습니다.
•
이에 따라, 파라미터의 잘못된 값을(자료형 측면) 명확하게 찾을 수 있습니다.
프로젝트 개요
본 프로젝트의 핵심은 Hydra를 통한 머신러닝 태스크의 설정 관리를 효율적으로 수행하는 것입니다.
머신러닝 태스크로서 이미지 분류(Image Classification) 문제를 선택하였으며, 모델링 코드와 관련된 세부 사항은 다루지 않음을 미리 말씀드립니다.
프로젝트의 전체 코드는 아래 링크에서 확인해주세요!
또한, 실제 프로젝트의 전체적인 트리 구조는 다음과 같습니다.
.
├── adapters.py
├── backbones.py
├── config_schemas
│ ├── init.py
│ ├── config_schema.py
│ ├── data_module_schema.py
│ ├── task
│ │ ├── init.py
│ │ ├── loss_function_schema.py
│ │ ├── model
│ │ │ ├── init.py
│ │ │ ├── adapter_schema.py
│ │ │ ├── backbone_schema.py
│ │ │ └── head_schema.py
│ │ ├── model_schema.py
│ │ └── optimizer_schema.py
│ ├── task_schema.py
│ └── trainer_schema.py
├── configs
│ ├── config.yaml
│ ├── data_module
│ │ ├── cifar10.yaml
│ │ └── mnist.yaml
│ ├── task
│ │ ├── cifar10_classification.yaml
│ │ ├── loss_function
│ │ │ └── cross_entropy.yaml
│ │ ├── mnist_classification.yaml
│ │ ├── model
│ │ │ ├── adapter
│ │ │ │ ├── linear_2048_10.yaml
│ │ │ │ └── linear_512_10.yaml
│ │ │ ├── cifar10_model.yaml
│ │ │ ├── head
│ │ │ │ └── identity_head.yaml
│ │ │ └── simple_model.yaml
│ │ └── optimizer
│ │ ├── adam.yaml
│ │ └── sgd.yaml
│ └── trainer
│ ├── cpu.yaml
│ └── gpu.yaml
├── data_modules.py
├── heads.py
├── loss_functions.py
├── models.py
├── tasks.py
└── train.py
트리 구조가 다소 복잡할 수 있어요
하지만, 본 프로젝트의 흐름을 이해하는 데 있어 아래의 트리 구조면 충분하다고 생각합니다
초록 글씨와 노란 바탕으로 표시한 컴포넌트가 핵심입니다!
.
├── config_schemas (Using Hydra Structured configs)
│ ├── config_schema.py
│ ├── data_module_schema.py
│ ├── task
│ │ ├── loss_function_schema.py
│ │ ├── model
│ │ │ ├── adapter_schema.py
│ │ │ ├── backbone_schema.py
│ │ │ └── head_schema.py
│ │ ├── model_schema.py
│ │ └── optimizer_schema.py
│ ├── task_schema.py
│ └── trainer_schema.py
├── configs
│ ├── config.yaml
│ ├── data_module
│ ├── task
│ │ ├── loss_function
│ │ ├── model
│ │ │ ├── adapter
│ │ │ ├── head
│ │ └── optimizer
│ └── trainer
└── train.py
먼저, Hydra의 Structured configs 기능을 사용하여 컴포넌트에 대한 스키마를 정의합니다 (config_schemas 폴더). 그 다음, config_schemas 폴더 에서 지정한 각 컴포넌트의 스키마 세부 사항은 configs 폴더 내부에서 구현합니다.
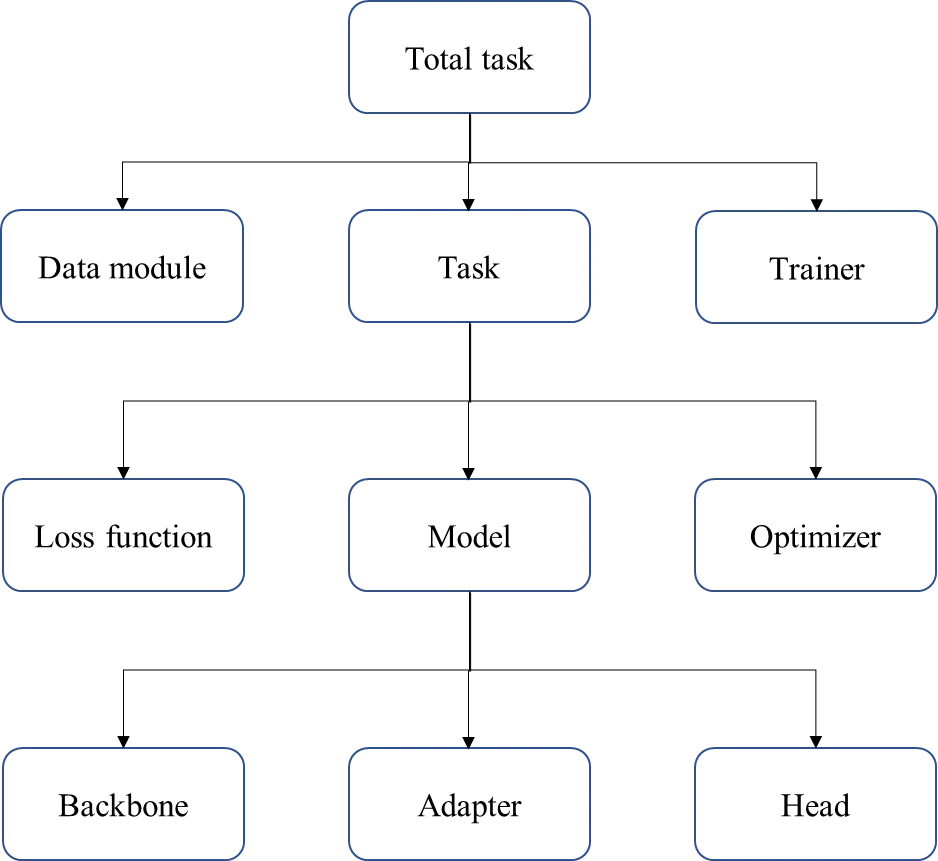
이때, 궁극적으로 본 프로젝트에서 풀고자 하는 문제를 컴포넌트 관점에서 설명드리면 아래와 같습니다.
<문제 정의>
•
어떠한 이미지 분류 문제를 수행할 것인가? → task 컴포넌트
◦
어떠한 모델을 사용할 것인가? → model 컴포넌트
▪
어댑터 모델은 무엇으로 할 것인가? → adapter 컴포넌트
▪
헤드 모델은 무엇으로 할 것인가? → head 컴포넌트
◦
손실 함수는 무엇을 사용할 것인가? → loss_function 컴포넌트
◦
최적화 알고리즘을 무엇을 사용할 것인가? → optimizer 컴포넌트
•
어떠한 이미지 데이터를 사용할 것인가? → data_module 컴포넌트
•
어떠한 학습 장치를 사용할 것인가? → trainer 컴포넌트
Hydra Structured configs를 사용할 경우, 각 컴포넌트를 하나의 노드(node) 단위로 관리할 수 있습니다. 따라서, 아래와 같은 장점이 있습니다.
•
각 컴포넌트의 파라미터 값을 독립적으로 관리할 수 있습니다.
•
각 컴포넌트 간의 관계를 명확하게 할 수 있습니다 (트리 구조로 생각하면 편해요)
)•
이에 따라, 전체적인 실험 설정을 간단하게 구조화할 수 있습니다.
정리
본 포스팅에서는 Hydra를 사용하면 얻을 수 있는 장점과, Hydra를 사용한 ML 미니 프로젝트 개요에 대하여 설명드렸습니다!
이제 Hydra를 적극적으로 사용해야 하는 이유를 이해하셨나요
이어지는 포스팅에서는 Hydra를 이용한 실험 설정 코드를 구체적으로 뜯어보는 시간을 가지도록 하겠습니다!
그럼 안녕히 가세요
Reference