
이번 포스팅에서는, Hydra 프레임워크를 이용하여 설정 파일을 어떻게 체계적으로 구성할 수 있는 지 확인하는 시간을 가져보도록 할게요
프로젝트의 전체 코드는 아래 링크에서 확인하시면 됩니다 :)
설정 관리 개요
구체적인 내용에 앞서, 지난 시간에 설명했던 프로젝트 구조를 떠올려봅시다.
.
├── config_schemas (Using Hydra Structured configs)
│ ├── config_schema.py
│ ├── data_module_schema.py
│ ├── task
│ │ ├── loss_function_schema.py
│ │ ├── model
│ │ │ ├── adapter_schema.py
│ │ │ ├── backbone_schema.py
│ │ │ └── head_schema.py
│ │ ├── model_schema.py
│ │ └── optimizer_schema.py
│ ├── task_schema.py
│ └── trainer_schema.py
├── configs
│ ├── config.yaml
│ ├── data_module
│ ├── task
│ │ ├── loss_function
│ │ ├── model
│ │ │ ├── adapter
│ │ │ ├── head
│ │ └── optimizer
│ └── trainer
└── train.py
설정 관리는 크게 스키마(schema_schemas 폴더) 구성과 세부 구현(configs 폴더)로 구성하였습니다.
•
스키마를 구성하여 각 컴포넌트의 토대를 구성합니다.
•
세부 구현을 통해 각 컴포넌트를 구성하는 요소를 정의합니다.
다음 그림은 지난 포스팅에서 사용하였던 컴포넌트 구조도입니다.
분명한 이해를 위하여 다시 동일한 구조도를 가져왔으며, 화살표를 받는 컴포넌트는 다른 컴포넌트에 포함됨을 의미합니다.
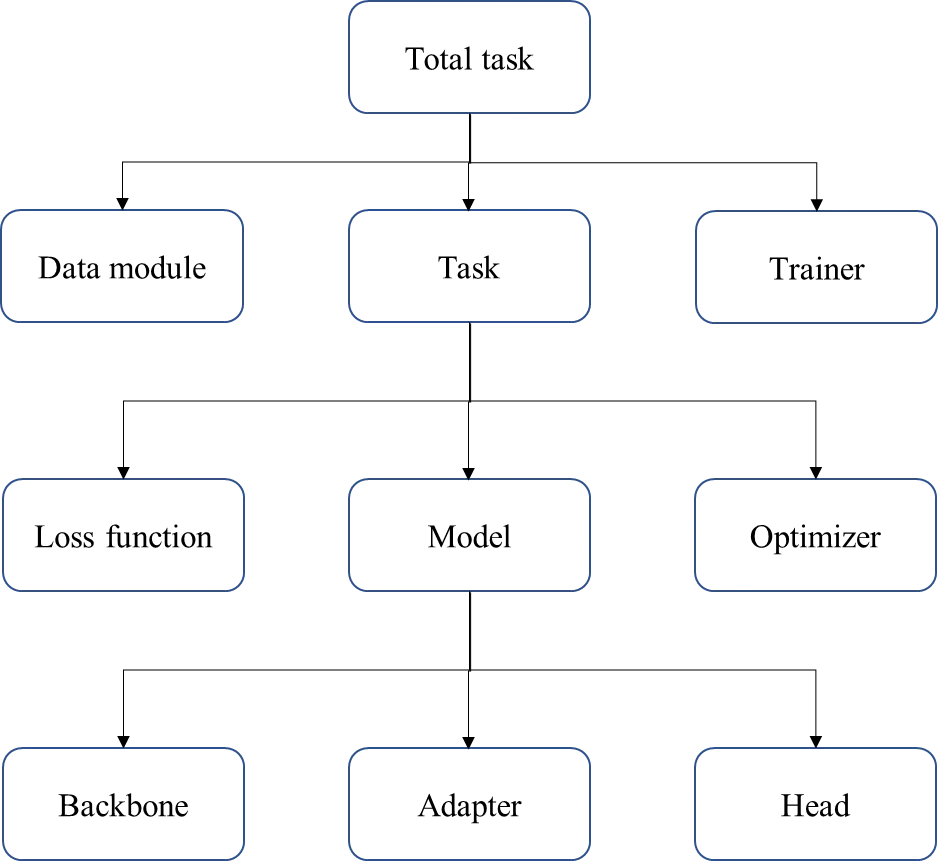
Total task 컴포넌트
본 컴포넌트는 프로젝트 전반을 담당하는 컴포넌트입니다.
해당 컴포넌트는 다음과 같이 구성됩니다.
•
Data module 컴포넌트 → 어떠한 이미지 데이터를 사용할 것인가?
•
Task 컴포넌트 → 어떠한 이미지 분류 문제를 수행할 것인가?
•
Trainer 컴포넌트 → 어떠한 학습 장치를 사용할 것인가?
스키마 폴더
먼저, 스키마 측면에서 코드를 살펴보겠습니다.
# ./config_schemas/config_schema.py
from omegaconf import MISSING
from hydra.core.config_store import ConfigStore
from pydantic.dataclasses import dataclass
from config_schemas import (
data_module_schema,
trainer_schema,
task_schema
)
@dataclass
class Config:
task: task_schema.TaskConfig = MISSING
data_module: data_module_schema.DataModuleConfig = MISSING
trainer: trainer_schema.TrainerConfig = MISSING
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(name="config_schema", node=Config)
task_schema.setup_config()
data_module_schema.setup_config()
trainer_schema.setup_config()
Python
복사
스키마 구성은 Hydra의 Structured config를 이용하였습니다.
Structured config를 사용하면, 각 컴포넌트를 하나의 노드로 관리할 수 있습니다. 따라서, 각 컴포넌트 간의 관계를 명확하게 할 수 있다는 장점이 있습니다. 마치 위에 제시한 구조도와 같이 말이죠!
또한, 원시 타입(Primitive type) 뿐만 아니라, 클래스도 컴포넌트의 요소로 지정 가능합니다. 이 점은, Argparse와 차별화되는 매우 중요한 특징이라고 생각합니다.
setup_config() 함수를 통해 Config store라는 곳에 모든 설정 정보를 저장합니다. 함수의 구체적인 내용은 다음과 같습니다.
•
Config store을 인스턴스화(instantiate)합니다. Config store는 프로젝트에 대한 모든 설정 노드 정보를 저장하기 위하여 사용됩니다. 일종의 설정 창고입니다.
•
노드의 이름은 config_schema이며, 설정 값으로서 Config 클래스를 채택합니다.
•
Config 클래스는 task, data_module, trainer 컴포넌트를 통해 구성됩니다. 각 컴포넌트의 세부 설정 값은 런타임 단계에서 정해집니다.
•
이때, MISSING 키워드를 통해 세부 구현을 뒤로 미룹니다. 지연 로딩(Lazy loading) 개념과 유사하다고 생각하시면 될 것 같아요!
•
MISSING 키워드가 표현되어 있을 시, 해당 컴포넌트의 설정 값은 반드시 런타임 과정에서 명시되어야 합니다. 그렇지 않으면, 설정을 인스턴스화 하여 실제 객체로 변환할 때 런타임 에러가 발생합니다.
•
마지막으로, task, data_module, trainer 컴포넌트의 설정 노드를 config store에 저장하는 함수를 호출합니다.
configs 폴더
그 다음은, 스키마에 대한 세부 구현에 대해 설명 드리겠습니다.
정말 간단한데요! YAML 파일을 통해 세부 사항을 구현하게 됩니다.
# ./configs/config.yaml
defaults:
- config_schema
- task: cifar10_classification
- data_module: cifar10
- trainer: gpu
YAML
복사
defaults 키워드를 통해 기본 설정을 정의합니다.
이때, config_schema 는 무엇인가? 앞서 Config store 설정 창고에 저장한 설정 노드의 이름입니다! config_schema 노드는 Config 클래스의 정보를 담고 있었지요. 결론적으로, 해당 YAML 파일에서 기본 골격으로 Config 클래스를 사용하겠다는 의미입니다.
아래 세 요소는 key-value 형식으로 구성된 것을 확인할 수 있는데요.
key의 경우 YAML 파일이 존재하는 폴더(컴포넌트)의 이름을, value의 경우 YAML 파일의 이름을 의미합니다.
이를 통해, 첫 줄에 제시한 config_schema 컴포넌트의 설정 값을 덮어 씌우는 원리로 동작하게 됩니다!
마지막으로, 런타임 때 각 설정 값으로 MISSING 키워드를 채우면서 인스턴스화를 수행합니다.
Data module 컴포넌트
다음은 Total task 컴포넌트 구성요소 중 하나인 Data module 컴포넌트에 대해 살펴보겠습니다.
스키마 폴더
스키마 코드는 다음과 같습니다.
# ./config_schemas/data_module_schema.py
from omegaconf import MISSING
from hydra.core.config_store import ConfigStore
from pydantic.dataclasses import dataclass
@dataclass
class DataModuleConfig:
_target_: str = MISSING
pin_memory: bool = True
drop_last: bool = True
batch_size: int = MISSING
num_workers: int = MISSING
data_dir: str = MISSING
@dataclass
class MNISTDataModuleConfig(DataModuleConfig):
_target_: str = "data_modules.MNISTDataModule"
@dataclass
class CIFAR10DataModuleConfig(DataModuleConfig):
_target_: str = "data_modules.CIFAR10DataModule"
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(
group="data_module",
name="mnist_data_module_schema",
node=MNISTDataModuleConfig
)
cs.store(
group="data_module",
name="cifar10_data_module_schema",
node=CIFAR10DataModuleConfig
)
Python
복사
본 코드에서는 눈여겨볼만한 점이 두 가지 있습니다
첫째, dataclass인 DataModuleConfig 클래스를 상속받는 클래스를 정의한 것입니다. 이게 무엇을 의미할까요?
Data module 컴포넌트는 어떠한 데이터를 사용할 것인가? 를 다룬다고 말씀드렸습니다. 그렇기 때문에, 이미지 분류에 사용되는 데이터가 다를 때, 새로운 클래스를 정의합니다. 본 프로젝트에서는 MNIST와 CIFAR10 데이터 셋을 사용할 것이므로, 두 개의 클래스를 정의했습니다.
cs.store() 함수 호출 시, group 파라미터 값으로 data_module 을 지정한 것에 주목하세요! 노드 그룹의 이름을 data_module 로 정의하고, 그룹에 속하는 노드 이름(name parameter)을 구분한 것입니다
둘째, _target_ 키워드입니다.
Hydra에서는 _target_ 키워드를 사용하여, 참조할 클래스를 지정할 수 있습니다. MNISTDataModuleConfig 클래스의 경우, data_modules.py 파일의 MNISTDataModule 클래스를 참조합니다.
또한, CIFAR10DataModuleConfig 클래스는 target으로 data_modules.py 파일의 CIFAR10DataModule 클래스를 참조합니다.
그 예시로, 아래 코드는 Pytorch-lighting 기반 MNISTDataModule 클래스의 실제 구현체입니다. 본 포스팅의 주요 목적은 설정 방법을 제시하는 것이므로, 자세한 설명은 넘어가도록 하겠습니다. 자세한 사항은 해당 레퍼런스를 참고해주세요!
# ./data_modules.py
from pytorch_lightning import LightningDataModule
from torch.utils.data import random_split, DataLoader
from torchvision.transforms import transforms
from torchvision.datasets import MNIST, CIFAR10
class MNISTDataModule(LightningDataModule):
def __init__(
self,
batch_size: int,
num_workers: int = 0,
pin_memory: bool = False,
drop_last: bool = False,
data_dir: str = "./",
):
super().__init__()
self.data_dir = data_dir
self.batch_size = batch_size
self.num_workers = num_workers
self.pin_memory = pin_memory
self.drop_last = drop_last
self.transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
def prepare_data(self):
MNIST(self.data_dir, train=True, download=True)
MNIST(self.data_dir, train=False, download=True)
def setup(self, stage=None):
if stage == "fit" or stage is None:
mnist_full = MNIST(self.data_dir, train=True, transform=self.transform)
self.mnist_train, self.mnist_val = random_split(mnist_full, [55000, 5000])
if stage == "test" or stage is None:
self.mnist_test = MNIST(self.data_dir, train=False, transform=self.transform)
def train_dataloader(self):
return DataLoader(
self.mnist_train,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.pin_memory,
drop_last=self.drop_last,
shuffle=True,
)
def val_dataloader(self):
return DataLoader(
self.mnist_val,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.pin_memory,
drop_last=self.drop_last,
shuffle=False,
)
def test_dataloader(self):
return DataLoader(
self.mnist_test,
batch_size=self.batch_size,
num_workers=self.num_workers,
pin_memory=self.pin_memory,
drop_last=self.drop_last,
shuffle=False,
)
Python
복사
configs 폴더
MNIST 데이터 모듈을 예시로 설명하겠습니다. 코드는 다음과 같아요 :)
# ./configs/trainer/gpu.yaml
defaults:
- cifar10_data_module_schema
batch_size: 64
num_workers: 8
data_dir: ./data/cifar10
YAML
복사
•
기본 스키마로서 cifar10_data_module_schema 노드 정보를 사용합니다.
•
defaults 키워드 외부에서 MISSING 상태였던 파라미터 값을 지정했습니다.
Trainer 컴포넌트
Trainer 컴포넌트는 Pytorch-lightning Trainer 클래스에 대한 설정 컴포넌트입니다.
Trainer 클래스 객체에 사용할 장비에 대한 스펙을 명시하는 부분으로 구성되어있습니다.
스키마 폴더
# ./config_schemas/trainer_schema.py
@dataclass
class TrainerConfig:
_target_: str = "pytorch_lightning.Trainer"
max_epochs: int = 10
precision: int = 16
log_every_n_steps: int = 10
accelerator: str = MISSING
devices: str = "auto"
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(
group="trainer",
name="trainer_schema",
node=TrainerConfig
)
Python
복사
TrainerConfig 클래스의 accelerator 변수가 MISSING 키워드로 정의되어 있습니다. 따라서, confings 폴더 내에서, 해당 변수의 값을 반드시 명시해주어야 합니다.
configs 폴더
# ./configs/trainer/gpu.yaml
defaults:
- trainer_schema
accelerator: gpu
YAML
복사
gpu.yaml 파일을 예시로 준비했습니다.
trainer_schema 노드에 TrainerConfig 클래스 정보가 저장되어있고, accelerator 값이 MISSING 인 상태입니다. 따라서, 해당 YAML 파일에서 gpu 값을 할당한 것을 확인할 수 있습니다
Task 컴포넌트
Task 컴포넌트는 ‘어떠한 문제를 풀 것인가?’에 대한 내용을 정의하는 부분입니다. 구성 컴포넌트는 아래와 같아요!
•
Model
•
Loss function
•
Optimizer
스키마 폴더
# ./config_schemas/task_schema.py
from config_schemas.task import (
loss_function_schema,
model_schema,
optimizer_schema
)
@dataclass
class TaskConfig:
_target_: str = MISSING
optimizer: optimizer_schema.OptimizerConfig = MISSING
model: model_schema.ModelConfig = MISSING
loss_function: loss_function_schema.LossFunctionConfig = MISSING
@dataclass
class MNISTClassificationTaskConfig(TaskConfig):
_target_: str = "tasks.MNISTClassification"
@dataclass
class CIFAR10ClassificationTaskConfig(TaskConfig):
_target_: str = "tasks.CIFAR10Classification"
model: model_schema.ModelConfig = MISSING
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(
group="task",
name="mnist_classfication_task_schema",
node=MNISTClassificationTaskConfig
)
cs.store(
group="task",
name="cifar10_classification_task_schema",
node=CIFAR10ClassificationTaskConfig
)
optimizer_schema.setup_config()
model_schema.setup_config()
loss_function_schema.setup_config()
Python
복사
크게 MNIST와 CIFAR10 이미지 분류 두 task에 대하여 설정 노드를 생성하였습니다.
•
MNIST → mnist_classfication_task_schema
•
CIFAR10 → cifar10_classification_task_schema
optimizer, loss_function, model 컴포넌트는 런타임 때 정의되는 부분이므로, MISSING 키워드를 사용하였습니다 (TaskConfig 클래스 정의).
configs 폴더
# ./configs/task/cifar10_classification.yaml
defaults:
- cifar10_classification_task_schema
- model: cifar10_model
- optimizer: sgd
- loss_function: cross_entropy
YAML
복사
cifar10_classification.yaml 파일을 예시로 준비하였습니다.
cifar10_classification_task_schema 라는 이름을 가진 설정 노드의 값을 기본으로 합니다.
해당 노드의 기본 값은 모두 MISSING 이었으므로, model / optimizer / loss_function에 대응되는 값을 모두 정의하였습니다.
•
model 폴더 → cifar10_model.yaml 참조
•
optimizer 폴더 → sgd.yaml 참조
•
loss_function 폴더 → cross_entropy.yaml 참조
Loss function 컴포넌트
해당 컴포넌트는 학습 과정에서 모델의 파라미터를 갱신하기 위하여, 어떠한 손실 함수(Loss function)을 사용할 지 정의하는 부분입니다.
스키마 폴더
# ./config_schemas/task/loss_function_schema.py
@dataclass
class LossFunctionConfig:
_target_: str = MISSING
@dataclass
class CrossEntropyLossFunctionConfig(LossFunctionConfig):
_target_: str = "torch.nn.CrossEntropyLoss"
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(
group="task/loss_function",
name="cross_entropy_loss_function_schema",
node=CrossEntropyLossFunctionConfig
)
Python
복사
여기서 주목할 점은 cs.store() 함수의 group 파라미터입니다!
따라서, group 파라미터를 명시할 때 task/loss_function 으로 정의하였습니다.
•
loss_function 는 Task 컴포넌트의 TaskConfig 클래스 변수임을 강조합니다!
•
Hydra에서는 그룹을 세분화(Top-down 방향)할 시, 반드시 / 문자를 사용해야합니다.
◦
상위그룹/하위그룹 → task/loss_function
Optimizer 컴포넌트
해당 컴포넌트는 모델 학습 과정에서, 파라미터를 갱신하기 위해 필요한 최적화 알고리즘을 정의하는 부분입니다.설정과 관련하여 매우 중요한 내용이 있으니 천천히 읽어주시기 바랍니다!
스키마 폴더
# ./config_schemas/task/optmizer_schema
@dataclass
class OptimizerConfig:
_target_: str = MISSING
_partial_: bool = True
lr: float = 0.0001
weight_decay: float = 0.0
@dataclass
class AdamOptimizerConfig(OptimizerConfig):
_target_: str = "torch.optim.Adam"
betas: tuple[float, float] = (0.9, 0.999)
eps: float = 1e-8
amsgrad: bool = False
@dataclass
class SGDOptimizerConfig(OptimizerConfig):
_target_: str = "torch.optim.SGD"
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(
group="task/optimizer",
name="adam_optimizer_schema",
node=AdamOptimizerConfig
)
cs.store(
group="task/optimizer",
name="sgd_optimizer_schema",
node=SGDOptimizerConfig
)
Python
복사
여기서 매우 특이한 키워드가 처음 등장하였습니다! 무엇일까요?
바로, _partial_ 키워드입니다! (OptimizerConfig 클래스)
왜 해당 키워드를 사용해야만 할까요? 한 번 아래의 코드를 보면서 설명 드리겠습니다.
task.py 파일 분석
# ./tasks.py
from typing import Callable, Iterator
from torch import Tensor, optim
from torchmetrics import Accuracy
from torch import nn
from pytorch_lightning import LightningModule
PARTIAL_OPTIMIZER_TYPE = Callable[[Iterator[nn.Parameter]], optim.Optimizer]
class TrainingTask(LightningModule):
def __init__(self, optimizer: PARTIAL_OPTIMIZER_TYPE) -> None:
super().__init__()
self.optimizer = optimizer
def configure_optimizers(self) -> optim.Optimizer:
return self.optimizer(params=self.parameters())
Python
복사
Pytorch-lightning의 LightningModule 클래스는 모델 학습의 방법을 정의하는 지침서 역할을 수행합니다.
•
어떠한 모델을 사용할 것인가?
•
모델의 입력과 출력을 어떻게 정의할 것인가?
•
모델 학습 과정을 어떻게 정의할 것인가?
따라서, LightningModule 클래스를 상속한 TrainingTask 클래스는 반드시 위 세 요소와 관련된 함수를 구현해야합니다. 자세한 내용은 레퍼런스를 확인해주세요!
저는 여기서, 모델 학습 정의와 관련한 configure_optimizers() 함수에 대해 설명하겠습니다. 함수 이름에서 알수 있지만, 최적화 알고리즘 객체를 생성하고 반환하는 역할을 수행해요.
이때, Pytorch (또는 Pytorch-lightning) 프레임워크의 특성 상, 최적화 객체를 정의할 때 반드시 모델의 파라미터를 params 인자로 받게됩니다.
하지만, 모델의 파라미터는 설정(Configuration) 단계가 아닌 런타임 단계에서 정의될 수 있어요
결과적으로, 설정 노드를 통해 최적화 알고리즘 객체를 만드는 시점은 모델이 정의된 시점 이후가 되어야 합니다!!!!
이 사실을 알려주는 키워드가 바로 OptimizerConfig 클래스의 _partial_ 키워드예요
tasks.py 파일에서도 TrainingTask 의 __init__ 함수를 호출할 때, optimizer 파라미터를 Callable 객체로 받는 것을 확인할 수 있습니다. 실제 Optimizer 클래스 객체는 configure_optimizers 함수를 호출할 때 생성이 됩니다.
configs 폴더
# ./configs/task/optimizer/sgd.yaml
defaults:
- sgd_optimizer_schema
lr: 5e-5
weight_decay: 0.2
YAML
복사
sgd.yaml 파일을 예시로 준비했어요.
task/optimizer 그룹에 속한 sgd_optimizer_schema 이름을 가진 노드의 값을 기본으로 하되, 일부 파라미터 값을 덮어 씌운 것을 확인할 수 있습니다.
Model 컴포넌트
Model 컴포넌트는 Task 컴포넌트에서 사용할 모델의 스펙을 정의하는 역할을 담당합니다. 크게 다음의 컴포넌트로 구성이 되어있어요.
•
Backbone
•
Adapter
•
Head
스키마 폴더
from config_schemas.task.model import (
adapter_schema,
backbone_schema,
head_schema
)
@dataclass
class ModelConfig:
_target_: str = MISSING
backbone: backbone_schema.BackboneConfig = MISSING
adapter: adapter_schema.AdapterConfig = MISSING
head: head_schema.HeadConfig = MISSING
@dataclass
class SimpleModelConfig(ModelConfig):
_target_: str = "models.SimpleModel"
@dataclass
class CIFAR10ModelConfig(ModelConfig):
_target_: str = "models.CIFAR10Model"
def setup_config() -> None:
cs = ConfigStore.instance()
cs.store(
group="task/model",
name="simple_model_schema",
node=SimpleModelConfig
)
cs.store(
group="task/model",
name="cifar10_model_schema",
node=CIFAR10ModelConfig
)
backbone_schema.setup_config()
adapter_schema.setup_config()
head_schema.setup_config()
Python
복사
configs 폴더
CIFAR10 Task에 해당하는 모델을 예시로 들겠습니다.
defaults:
- cifar10_model_schema
- backbone: resnet18_schema
- adapter: linear_512_10
- head: identity_head
YAML
복사
backbone, adapter, head 컴포넌트의 스펙을 해당 파일에서 정의해주는 것을 확인할 수 있습니다.
위 세 컴포넌트의 구조도 앞서 설명 드린 컴포넌트의 구조와 동일합니다.
정리
이번 시간에는 각 컴포넌트의 설정 구현에 대하여 설명드렸습니다.
다음 포스팅에서는 구성한 컴포넌트의 설정을 바탕으로, 머신러닝 task를 어떻게 수행하는 지를 다루겠습니다!!
그럼 안녕히 가세요