

안녕하세요!
드디어 Amazon 상품 가격 예측 봇 구축기 마지막 세션입니다.
오늘은 오픈소스 모델을 대표하는 Llama-3.1을 파인튜닝하고, 성능을 평가하도록 하겠습니다.
•
데이터 전처리
•
Baseline 모델 생성
•
LLM 파인튜닝 with GPT
•
LLM 파인튜닝 with LLAMA
과연, 이번 프로젝트에서는 Llama가 GPT를 뛰어넘을 수 있을까요?
바로 출발하시죠~
LLM 파인튜닝 with Llama3
저는 A100 모델을 활용하기위해, Google Colaboratory 플랫폼을 사용했습니다.
따라서, Colab 관련 코드가 일부 포함되어 있음을 미리 알려드립니다 :)
라이브러리 로드 및 환경 설정
먼저, Llama 모델 파인튜닝과 평가에 관련된 라이브러리를 불러와요.
Open-source model 설정을 위해 transformers 라이브러리를 불러옵니다.
또한, LoRA(Low-Rank Adaptation) 기반 학습을 위해 peft 라이브러리도 포함했습니다.
마지막으로, 모델의 지도 학습 설정을 위한 trl 라이브러리도 함께합니다.
# imports
import os
import re
from datetime import datetime
import torch
import transformers
import wandb
import matplotlib.pyplot as plt
from google.colab import userdata
from huggingface_hub import login
from transformers import AutoModelForCasualLM, AutoTokenizer, TrainingArguments, BitsAndBytesConfig, set_seed
from datasets import load_dataset
from peft import LoraConfig
from trl import SFTTrainer, SFTConfig
# Constants - used for printing to stdout in color
GREEN = "\033[92m"
YELLOW = "\033[93m"
RED = "\033[91m"
RESET = "\033[0m"
COLOR_MAP = {"red":RED, "orange": YELLOW, "green": GREEN}
%matplotlib inline
Python
복사
변수 설정
파인튜닝 데이터 준비 및 파인튜닝에 필요한 변수를 정의합니다.
먼저, 사용할 LLM 모델의 이름과 원천 데이터 저장소를 지정합니다.
한편, 본 프로젝트에서는 GPU를 점유하는 메모리를 최소화하기 위해, QLoRA 기반 파인튜닝을 수행합니다.
이에 따라, 관련 파라미터를 설정하였습니다. 또한, Target Module의 경우 권장 사항에 따라, Head Attention Module을 선택했습니다.
# Hugging Face Setup
BASE_MODEL = "meta-llama/Meta-Llama-3.1-8B"
PROJECT_NAME = "Pricer-FineTune-OpenSource"
HF_USER = "jeffrey03"
# Data
DATASET_NAME = f"{HF_USER}/amazon-item-price-data-lite-version"
MAX_SEQUENCE_LENGTH = 182
# Run name for saving the model in the hub
RUN_NAME = f"{datetime.now():%Y-%m-%d_%H.%M.%S}"
PROJECT_RUN_NAME = f"{PROJECT_NAME}-{RUN_NAME}"
HUB_MODEL_NAME = f"{HF_USER}/{PROJECT_RUN_NAME}"
# Hyperparameters for QLoRA
LORA_R = 32
LORA_ALPHA = 64
TARGET_MODULES = ["q_proj", "v_proj", "k_proj", "o_proj"]
LORA_DROPOUT = 0.1
QUANT_4_BIT = True
# Hyperparameters for Training
EPOCHS = 3
BATCH_SIZE = 16
GRADIENT_ACCUMULATION_STEPS = 2
LEARNING_RATE = 1e-4
LR_SCHEDULER_TYPE = 'cosine'
WARMUP_RATIO = 0.03
OPTIMIZER = "paged_adamw_32bit"
# Admin config
STEPS = 50
SAVE_STEPS = 250
LOG_TO_WANDB = True
Python
복사
환경 변수 설정
파인튜닝 데이터 다운로드 및 Weights & Biases 플랫폼 접근에 필요한 환경 변수를 설정합니다
# HuggingFace
hf_token = userdata.get('HF_TOKEN')
login(hf_token, add_to_git_credential=True)
# Weights & Biases
wandb_api_key = userdata.get('WANDB_API_KEY')
os.environ['WANDB_API_KEY'] = wandb_api_key
wandb.login()
# Configure Weights & Biases to record against our project
os.environ["WANDB_PROJECT"] = PROJECT_NAME
os.environ["WANDB_LOG_MODEL"] = "true" if LOG_TO_WANDB else "false"
os.environ["WANDB_WATCH"] = "gradients"
# Set up project in Weights & Biases Platform
if LOG_TO_WANDB:
wandb.init(project=PROJECT_NAME, name=RUN_NAME)
Python
복사
데이터 로드
허깅페이스 Dataset API를 통해, 레포지토리에 업로드한 데이터를 불러옵니다.
dataset = load_dataset(DATASET_NAME)
train = dataset['train']
validation = dataset['validation']
test = dataset['test']
Python
복사
# Remind ourselves the training set
print(train[0])
>>
{'text': "How much does this cost to the nearest dollar?\n\nAluminum Manual Truck & Trailer Hand Crank Tarp Kit w/wo Tarp (Hand Crank ONLY (NO TARP))\nAll Truck Products EZ-Mount Dump Tarp Roller Kits are built for dump truck and dump trailer tarp applications. The extruded aluminum roller axle telescopes to the exact width of your truck. The tarp can attach to the roller with a tarp pocket or by preformed slot in the roller to bolt through the tarp's grommets. The kit includes crank handle, mounting brackets with bearings, tarp roller, Mesh Tarp, 20 ft pull-rope, 4 rope storing J-hooks, two rubber tarp straps with S-hooks, and mounting and tarp bolts. Dimensions 47 x 5.5 x 5.\n\nPrice is $144.00",
'price': 143.99}
Python
복사
# Remind a test set
print(test[0])
>>
{'text': 'How much does this cost to the nearest dollar?\n\nKOHLER Triton Centerset Lavatory Faucet, Polished Chrome (Handles Not Included)\nFrom the Manufacturer With practical design and solid brass construction, Triton faucets are an exceptional value. Competitively priced Triton faucets feature washerless ceramic valving, a durable Polished Chrome finish and vandal-resistant index buttons. The two-handle centerset faucet will hold up to years of daily use. Select from a choice of lever, cross, square or wristblade handle style options. (Handles Not Included) Two-handle centerset lavatory faucet for 4-inch centers KOHLER ceramic disc valves exceed industry longevity standards two times for a lifetime of durable performance Solid brass construction for durability and reliability Choose from lever, cross, square, or wristblade handle options For installation on 4-inch\n\nPrice is $',
'price': 336.28}
Python
복사
모델 및 토크나이저 준비
LoRA(or QLoRA) 기반 파인튜닝에 필요한 모델과 토크나이저를 준비합니다.
# Quantization
if QUANT_4_BIT:
quant_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_compute_dtype=torch.bfloat16,
bnb_4bit_quant_type="nf4"
)
else:
quant_config = BitsAndBytesConfig(
load_in_8bit=True,
bnb_8bit_compute_dtype=torch.bfloat16
)
Python
복사
•
QLoRA에 필요한 설정 값을 정의합니다. 4-bit 또는 8-bit 기반 모델 양자화 중 한 가지를 선택합니다.
# Load the Tokenizer and the Model
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL, trust_remote_code=True)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "right"
base_model = AutoModelForCasualLM.from_pretrained(
BASE_MODEL,
quantization_config=quant_config,
device_map="auto"
)
base_model.generation_config.pad_token_id = tokenizer.pad_token_id
print(f"Memory footprint: {base_model.get_memory_footprint() / 1e6:.1f} MB")
>> Memory footprint: 5591.5 MB
Python
복사
•
[tokenizer.pad_token = tokenizer.eos_token] 코드와 관련한 주의사항
◦
파인튜닝 수행 시, LLM 모델이 문장의 끝을 인식하지 못하고, 계속 토큰을 생성하는 경우가 발생할 수 있습니다.
◦
이때는, tokenizer의 configuration 파트에 직접 pad_token 값을 지정해야합니다. → padding에 대응하는 special token을 등록합니다.
•
LLM 모델 객체를 생성할 때, 양자화 설정 값을 매개변수로 전달합니다.
Data Collator 정의
Data Collator는 데이터를 배치 단위로 묶은 후, 모델에 입력하기 이전에 전처리를 수행합니다.
본래 Data Collator는 필수 사항이 아니지만, 본 프로젝트에서는 해당 요소를 반드시 정의해야합니다.
왜냐하면, 우리의 목적은 제품의 가격을 정확하게 예측하는 것이지, 제품의 설명을 예측하는 것이 아니기 때문입니다. 다시 말해, 모델이 제품 설명을 참고하여 가격을 예측할 수 있도록 해야합니다.
from trl import DataCollatorForCompletionOnlyLM
response_template = "Price is $"
collator = DataCollatorForCompletionOnlyLM(response_template, tokenizer=tokenizer)
Python
복사
•
response_template 설정을 통해, 모델이 해당 문자열 이후에 등장할 토큰들을 차례로 예측할 수 있도록합니다.
•
DataCollatorForCompletionOnlyLM : 학습의 입력 문장 중 response_template을 포함한 이전 token들의 label을 -100으로 설정합니다. 즉, 모델은 제품 설명에 대응하는 토큰 집합을 학습하지 않습니다. 대신, 주response_template 이후 토큰(or 토큰 시퀀스) 만을 학습합니다.
파인튜닝 설정
QLoRA 기반 Supervised Fine-tuning(SFT)에 필요한 파라미터를 정의합니다.
# LoRA
lora_parameters = LoraConfig(
lora_alpha=LORA_ALPHA,
lora_dropout=LORA_DROPOUT,
r=LORA_R,
bias="none",
task_type="CAUSAL_LM",
target_modules=TARGET_MODULES,
)
# SFT
train_parameters = SFTConfig(
output_dir=PROJECT_RUN_NAME,
num_train_epochs=EPOCHS,
per_device_train_batch_size=BATCH_SIZE,
per_device_eval_batch_size=4,
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS,
optim=OPTIMIZER,
save_steps=SAVE_STEPS,
save_total_limit=2,
logging_steps=STEPS,
learning_rate=LEARNING_RATE,
weight_decay=0.001,
fp16=False,
bf16=True,
max_grad_norm=0.3,
max_steps=-1,
warmup_ratio=WARMUP_RATIO,
group_by_length=True,
lr_scheduler_type=LR_SCHEDULER_TYPE,
report_to="wandb" if LOG_TO_WANDB else None,
run_name=RUN_NAME,
max_seq_length=MAX_SEQUENCE_LENGTH,
dataset_text_field="text",
save_strategy="steps",
hub_strategy="checkpoint",
push_to_hub=True,
hub_model_id=HUB_MODEL_NAME,
hub_private_repo=False,
eval_strategy="steps",
# eval_on_start=True,
metric_for_best_model='eval_loss',
greater_is_better=False,
load_best_model_at_end=True,
seed=42
)
# SFT Trainer
fine_tuning = SFTTrainer(
model=base_model,
train_dataset=train, # Dataset for training
eval_dataset=validation, # Dataset for validation
peft_config=lora_parameters, # LoRA Configuration
tokenizer=tokenizer,
args=train_parameters, # SFT Configuration
data_collator=collator # Data Collator
)
Python
복사
•
N(50) step 단위로 모델 검증을 수행합니다. 검증용 loss 값을 측정하여, top-K(2)개의 모델 파라미터를 HuggingFace 저장소에 push합니다.
•
모델이 안정적으로 동작하는지 살펴보기 위해, sanity check가 필수입니다(eval_on_start=True). 하지만, colab 에서는 이상하게 error가 발생하네요. 정확한 원인을 발견하지 못했으나, 일단 주석 처리를 했습니다.
파인튜닝 수행
드디어.. 드디어!!!! Llama-3.1-8B 모델을 파인튜닝합니다.
# Fine-tune!
fine_tuning.train()
# Push our fine-tuned model to Hugging Face
fine_tuning.model.push_to_hub(PROJECT_RUN_NAME, private=False)
if LOG_TO_WANDB:
wandb.finish()
Python
복사
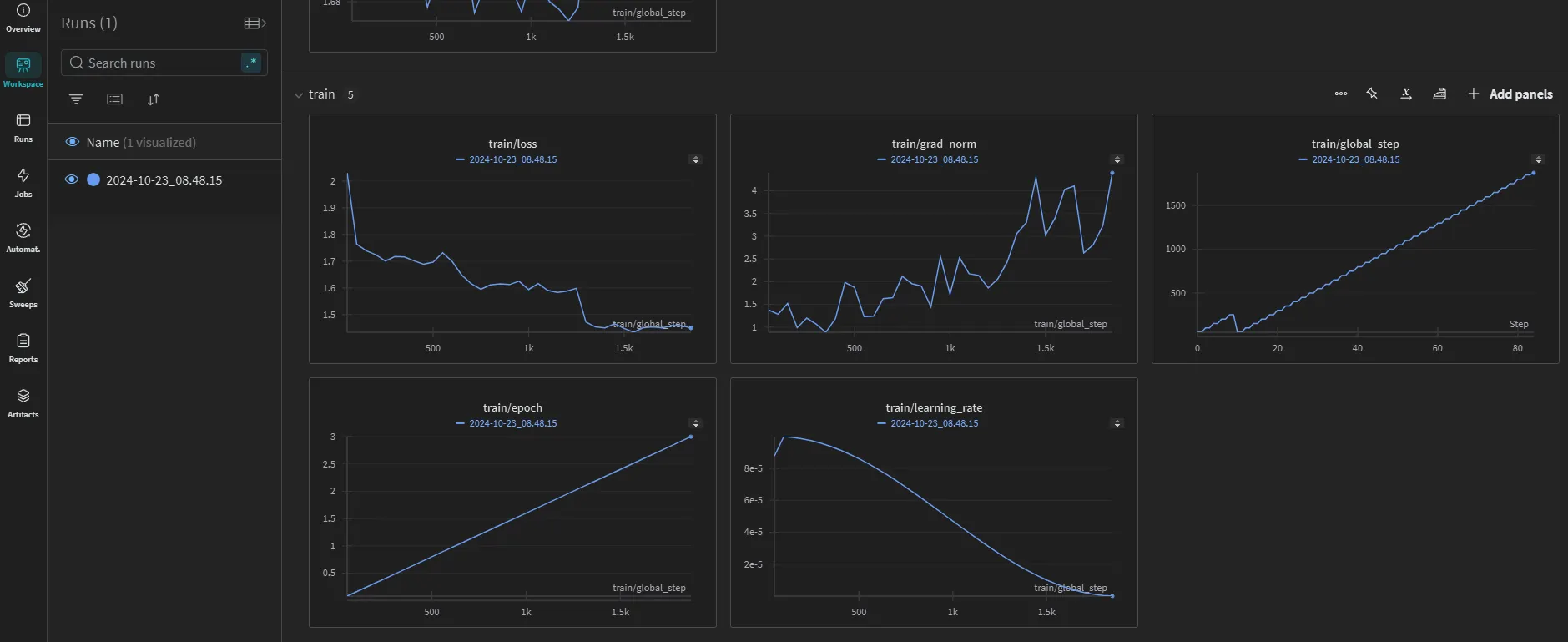
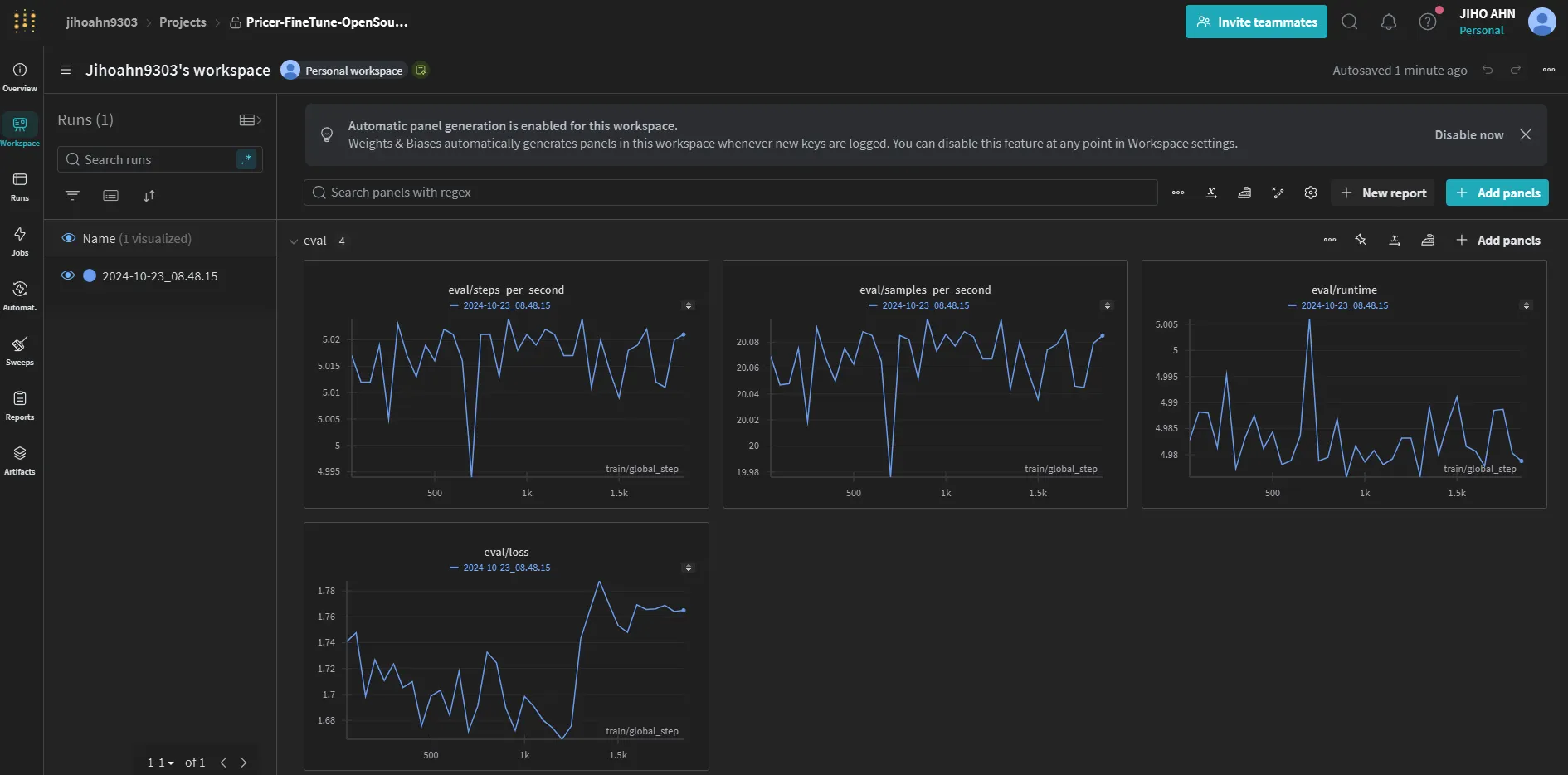
파인튜닝 모델 평가
이제 파인튜닝이 끝난 gpt-4o-mini 모델을 평가해봅시다!
얼마나 가격을 정확하게 예측할 수 있을까요?!
Baseline 모델 평가에 사용한 Tester 클래스를 이 곳에서도 동일하게 사용합니다.
from peft import PeftModel
# Commit hash for best model
REVISION = "7c5d50df4f9a99b4eb7ef8790c47bad64da41bdd"
FINETUNED_MODEL_REPO = f"{HF_USER}/{PROJECT_RUN_NAME}"
# Load fine-tuned model(Best model)
FINETUNED_MODEL = PeftModel.from_pretrained(base_model, FINETUNED_MODEL_REPO, revision=REVISION)
# A utility function to extract the price from a string
def get_price(s):
s = s.replace('$','').replace(',','')
match = re.search(r"[-+]?\d*\.\d+|\d+", s)
return float(match.group()) if match else 0
# Original prediction function takes the most likely next token
def model_predict(prompt):
set_seed(42)
inputs = tokenizer.encode(prompt, return_tensors="pt").to("cuda")
attention_mask = torch.ones(inputs.shape, device="cuda")
outputs = FINETUNED_MODEL.generate(inputs, attention_mask=attention_mask, max_new_tokens=3, num_return_sequences=1)
response = tokenizer.decode(outputs[0])
return extract_price(response)
Tester.test(model_predict, data=test)
>>>
1: Guess: $81.00 Truth: $336.28 Error: $255.28 SLE: 2.00 Item: KOHLER Triton Center...
2: Guess: $7.00 Truth: $3.22 Error: $3.78 SLE: 0.41 Item: HUYGHAVO Sports Patt...
3: Guess: $170.00 Truth: $182.99 Error: $12.99 SLE: 0.01 Item: WERFACTORY Tiffany F...
...
248: Guess: $220.00 Truth: $429.00 Error: $209.00 SLE: 0.44 Item: Arotikee Modern Gold...
249: Guess: $1.00 Truth: $1.04 Error: $0.04 SLE: 0.00 Item: Cosmas® 9985SN Satin...
250: Guess: $19.00 Truth: $13.99 Error: $5.01 SLE: 0.08 Item: welltop Egg Holder f...
Python
복사
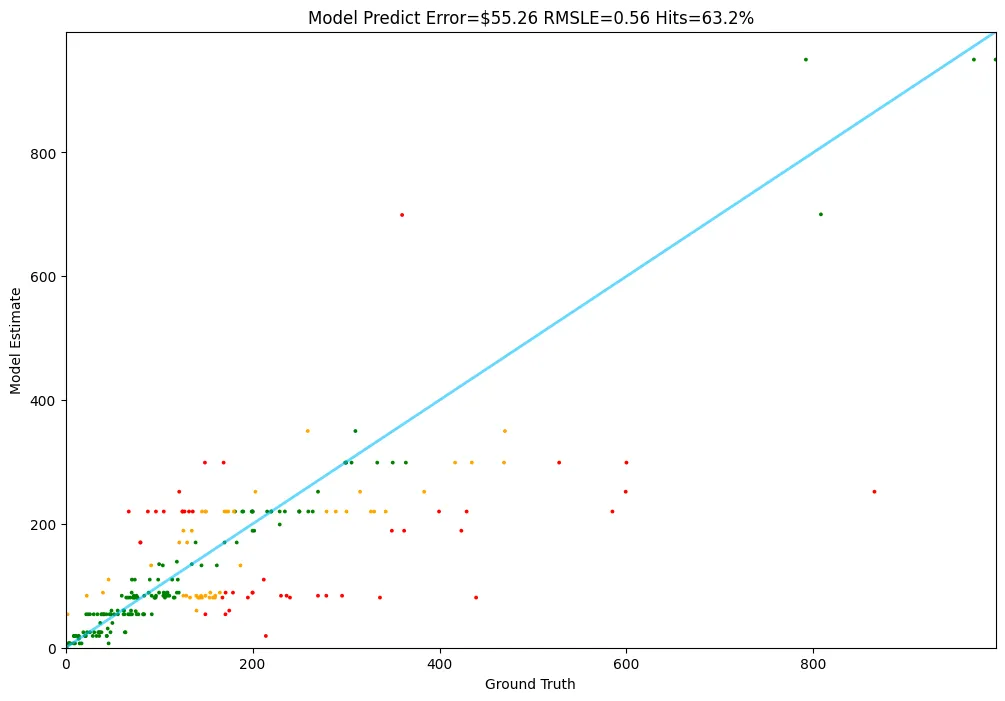
Baseline 모델 목록 | 평균 예측 오차(MAE, $) | SLE | Hit ratio(%) |
Random Model | 390.09 | 1.97 | 7.2 |
Linear Regression Model | 99.09 | 1.14 | 25.6 |
Linear Regression + Word2Vec | 86.52 | 1.02 | 38.4 |
Support Vector Machine | 82.29 | 0.91 | 46.8 |
GPT-4o-Mini with Fine-tuning | 66.51 | 0.61 | 57.2 |
Meta-Llama-3.1-8B with Fine-tuning | 55.32 | 0.56 | 63.2 |
힘의 차이가 느껴지시나요?
이번 프로젝트에서는 Llama-3.1-8B 기반 파인튜닝 모델이 제일 가격을 잘 맞추네요! 상을 줘야겠습니다
정리
긴 글 읽느라 고생하셨습니다
우리는 총 네 개의 세션을 거쳐 아름다운 가격 예측 봇을 만들었어요.
제품 설명을 참고하여 가격을 예측할 수 있다는 것이 정말 아름답습니다.
물론 아직 개선할 수 있는 사항이 많이 있습니다. 예를 들면, 다음과 같은 것들이 있어요.
•
데이터 보충: 데이터 전처리 세션에서 봤듯이, 일부 카테고리 또는 가격대에 대부분의 제품이 포진하고 있습니다. 추가 데이터 수집 또는 데이터 합성 등의 방법을 적용하여, 데이터를 보충할 수 있습니다. 이렇게 하면, 조금 더 범용적인 가격 예측 봇을 만들 수 있겠지요
•
토큰 길이 확장: 토큰의 길이를 확장하여, LLM 모델에게 제품의 정보를 조금 더 제공할 수 있습니다. 자세한 설명을 제공할수록, 모델이 가격을 더 정확하게 예측할 수도 있습니다.
•
학습 데이터 추가 제공: 본 프로젝트에서는, LLM 모델의 컴퓨팅 시간 관계 상 일부 학습 데이터만 활용했습니다. 하지만, 비용 측면에서 여유가 있다면, 전체 학습 데이터셋을 모델에 입력하여 학습을 수행할 수 있습니다.
•
분산 학습 수행: 분산 학습 아키텍처를 적용하여, 전체 학습 시간을 줄일 수 있습니다. 이에 따라, 서로 다른 모델을 비교하여, 우리가 설정한 task에 가장 적합한 모델을 빠르게 찾을 수 있어요!
다음에 더 좋은 주제로 찾아오도록 할게요.
그때까지 안녕